What is Word Embedding?
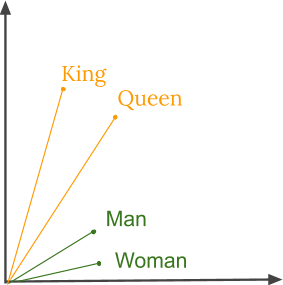
Humans have always excelled at understanding languages. It is easy for humans to understand the relationship between words but for computers, this task may not be simple. For example, we humans understand the words like king and queen, man and woman, tiger and tigress have a certain type of relation between them but how can a computer figure this out?
Word embeddings are basically a form of word representation that bridges the human understanding of language to that of a machine. They have learned representations of text in an n-dimensional space where words that have the same meaning have a similar representation. Meaning that two similar words are represented by almost similar vectors that are very closely placed in a vector space. These are essential for solving most Natural language processing problems.
Thus when using word embeddings, all individual words are represented as real-valued vectors in a predefined vector space. Each word is mapped to one vector and the vector values are learned in a way that resembles a neural network.
Word2Vec is one of the most popular technique to learn word embeddings using shallow neural network. It was developed by Tomas Mikolov in 2013 at Google.

Why Word Embeddings are used?
As we know the machine learning models cannot process text so we need to figure out a way to convert these textual data into numerical data. Previously techniques like Bag of Words and TF-IDF have been discussed that can help achieve use this task. Apart from this, we can use two more techniques such as one-hot encoding, or we can use unique numbers to represent words in a vocabulary. The latter approach is more efficient than one-hot encoding as instead of a sparse vector, we now have a dense one. Thus this approach even works when our vocabulary is large.
In the below example, we assume we have a small vocabulary containing just four words, using the two techniques we represent the sentence ‘Come sit down’.
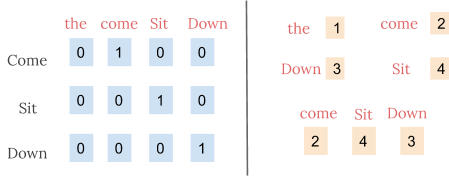
However, the integer-encoding is arbitrary as it does not capture any relationship between words. It can be challenging for a model to interpret, for example, a linear classifier learns a single weight for each feature. Because there is no relationship between the similarity of any two words and the similarity of their encodings, this feature-weight combination is not meaningful.
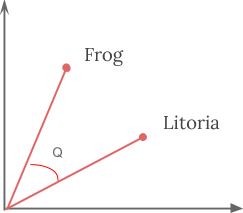
Thus by using word embeddings, words that are close in meaning are grouped near to one another in vector space. For example, while representing a word such as frog, the nearest neighbour of a frog would be frogs, toads, Litoria. This implies that it is alright for a classifier to not see the word Litoria and only frog during training, and the classifier would not be thrown off when it sees Litoria during testing because the two-word vectors are similar. Also, word embeddings learn relationships. Vector differences between a pair of words can be added to another word vector to find the analogous word. For example, “man” -“woman” + “queen” ≈ “king”.
What is word2Vec?
Word2vec is a method to efficiently create word embeddings by using a two-layer neural network. It was developed by Tomas Mikolov, et al. at Google in 2013 as a response to make the neural-network-based training of the embedding more efficient and since then has become the de facto standard for developing pre-trained word embedding.
The input of word2vec is a text corpus and its output is a set of vectors known as feature vectors that represent words in that corpus. While Word2vec is not a deep neural network, it turns text into a numerical form that deep neural networks can understand.
The Word2Vec objective function causes the words that have a similar context to have similar embeddings. Thus in this vector space, these words are really close. Mathematically, the cosine of the angle (Q) between such vectors should be close to 1, i.e. angle close to 0.
Word2vec is not a single algorithm but a combination of two techniques – CBOW(Continuous bag of words) and Skip-gram model. Both of these are shallow neural networks which map word(s) to the target variable which is also a word(s). Both of these techniques learn weights which act as word vector representations.
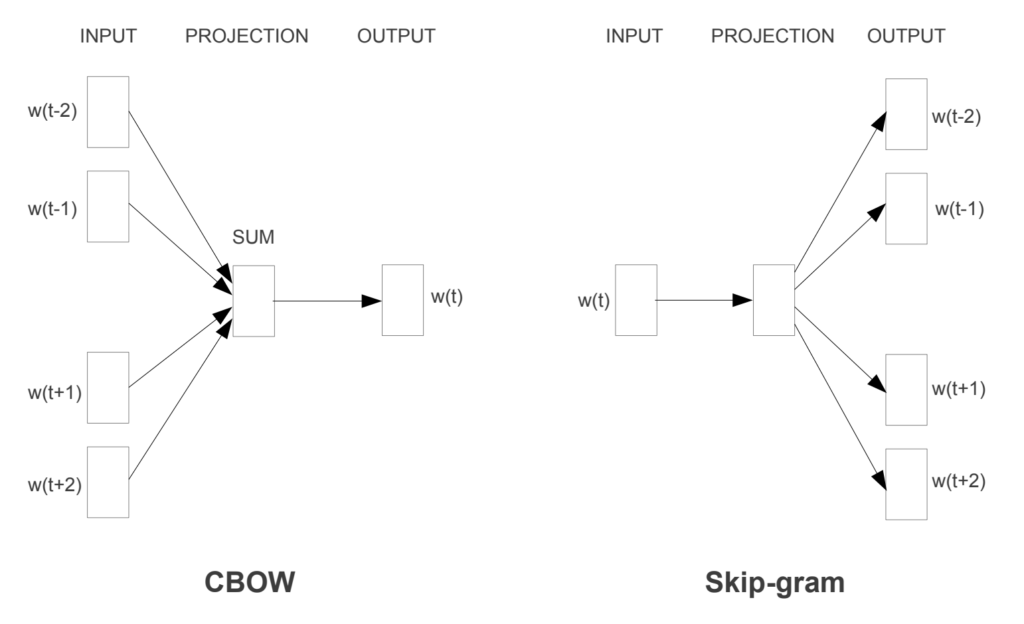
Continuous Bag-of-Words model (CBOW)
CBOW predicts the probability of a word to occur given the words surrounding it. We can consider a single word or a group of words. But for simplicity, we will take a single context word and try to predict a single target word.
The English language contains almost 1.2 million words, making it impossible to include so many words in our example. So I ‘ll consider a small example in which we have only four words i.e. live, home, they and at. For simplicity, we will consider that the corpus contains only one sentence, that being, ‘They live at home’.
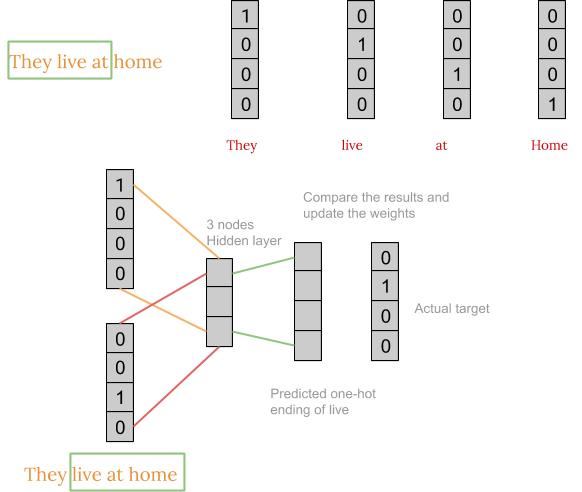
First, we convert each word into a one-hot encoding form. Also, we’ll not consider all the words in the sentence but ll only take certain words that are in a window. For example for a window size equal to three, we only consider three words in a sentence. The middle word is to be predicted and the surrounding two words are fed into the neural network as context. The window is then slid and the process is repeated again.
Finally, after training the network repeatedly by sliding the window a shown above, we get weights which we use to get the embeddings as shown below.
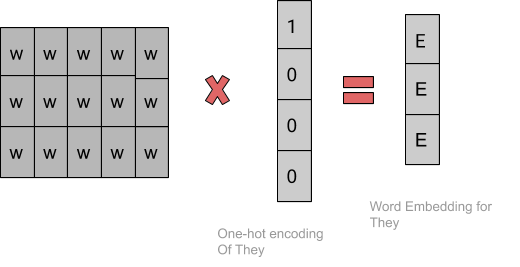
Usually, we take a window size of around 8-10 words and have a vector size of 300.
Skip-gram model
The Skip-gram model architecture usually tries to achieve the reverse of what the CBOW model does. It tries to predict the source context words (surrounding words) given a target word (the centre word)
The working of the skip-gram model is quite similar to the CBOW but there is just a difference in the architecture of its neural network and the way the weight matrix is generated as shown in the figure below:
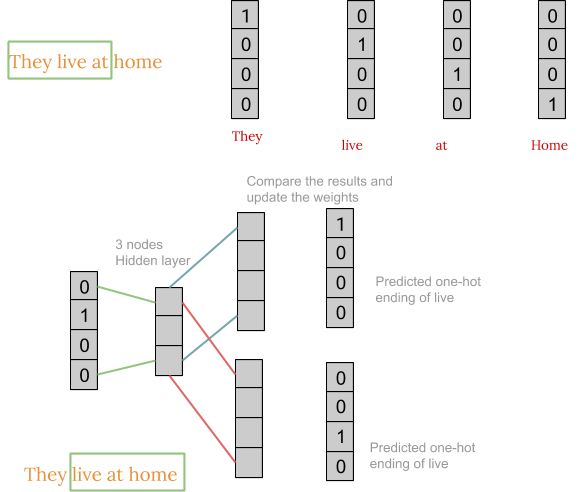
After obtaining the weight matrix, the steps to get word embedding is same as CBOW.
So now which one of the two algorithms should we use for implementing word2vec? Turns out for large corpus with higher dimensions, it is better to use skip-gram but is slow to train. Whereas CBOW is better for small corpus and is faster to train too.
GloVe
GloVe (Global Vectors for Word Representation) is an alternate method to create word embeddings. It is based on matrix factorization techniques on the word-context matrix. A large matrix of co-occurrence information is constructed and you count each “word” (the rows), and how frequently we see this word in some “context” (the columns) in a large corpus. Usually, we scan our corpus in the following manner: for each term, we look for context terms within some area defined by a window-size before the term and a window-size after the term. Also, we give less weight for more distant words.
The number of “contexts” is, of course, large, since it is essentially combinatorial in size. So then we factorize this matrix to yield a lower-dimensional matrix, where each row now yields a vector representation for each word. In general, this is done by minimizing a “reconstruction loss”. This loss tries to find the lower-dimensional representations which can explain most of the variance in the high-dimensional data.
In practice, we use both GloVe and Word2Vec to convert our text into embeddings and both exhibit comparable performances. Although in real applications we train our model over Wikipedia text with a window size around 5- 10. The number of words in the corpus is around 13 million, hence it takes a huge amount of time and resources to generate these embeddings. To avoid this we can use the pre-trained word vectors that are already trained and we can easily use them. Here are the links to download pre-trained Word2Vec or GloVe.
This brings us to the end of this article where we learned about word embedding and some popular techniques to implement them.