


- What Is Semi-Supervised Learning?
- How Does Semi-Supervised Learning Work?
- Why Use Semi-Supervised Learning?
- Advantages and Disadvantages of Semi-Supervised Learning
- Real-World Applications of Semi-Supervised Learning
- Popular Semi-Supervised Learning Algorithms
- Challenges of Semi-Supervised Learning
- Future of Semi-Supervised Learning
- Frequently Asked Questions(FAQ's)
In the evolving landscape of machine learning, data is the ultimate fuel. But what happens when you have limited labeled data and tons of unlabeled data lying around? This is where Semi-Supervised Learning (SSL) comes into play.
Striking the perfect balance between supervised and unsupervised learning, semi-supervised learning empowers models to make accurate predictions while reducing the cost of data labeling.
In this article, we will break down what semi-supervised learning is, why it matters, how it works, real-world applications, and the challenges you should consider when working with it.
What Is Semi-Supervised Learning?
Semi-Supervised Learning is a machine learning approach that uses a small amount of labeled data combined with a large amount of unlabeled data to train models. Unlike supervised learning, which relies entirely on labeled datasets, and unsupervised learning, which uses none, semi-supervised learning sits in the middle.
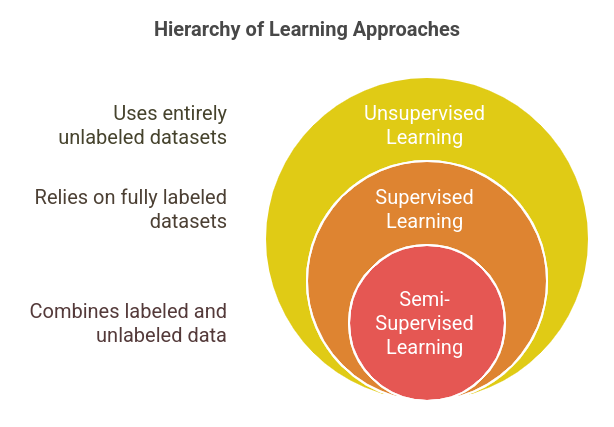
Why is this important?
Because labeling data is expensive, time-consuming, and often requires domain expertise. On the other hand, collecting raw, unlabeled data is much easier. Semi-supervised learning bridges this gap, allowing us to maximize model performance with minimal labeled data.
Also Read: What is Data Collection?
How Does Semi-Supervised Learning Work?
The typical semi-supervised learning process follows these steps:
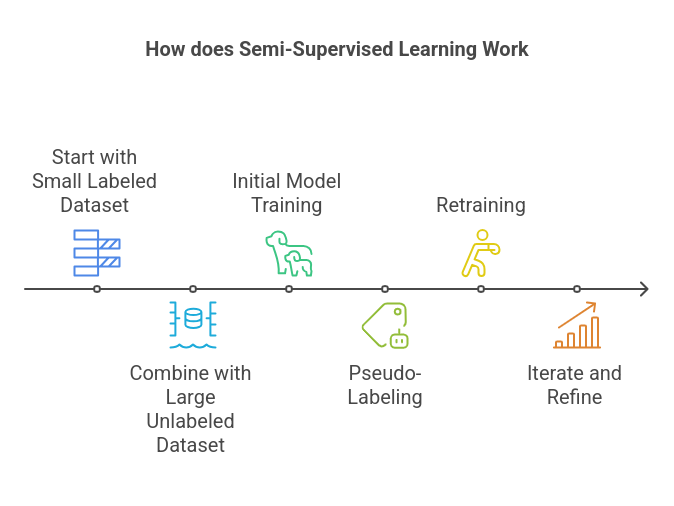
- Start with a small labeled dataset: These are your “ground truths” from which the model can learn directly.
- Combine with a large unlabeled dataset: These are the data points you have but without labels.
- Initial model training: The model is trained on the labeled data.
- Pseudo-labeling: The trained model predicts labels for the unlabeled data.
- Retraining: The model is retrained using both the original labeled data and the pseudo-labeled data.
- Iterate and refine: This loop continues until performance stabilizes or reaches a desired level.
This method leverages the model’s ability to generalize from a small, high-quality labeled dataset and scale its learning with abundant unlabeled data.
Why Use Semi-Supervised Learning?
Here are some key reasons why semi-supervised learning has gained attention:
- Reduced labeling costs: You don’t need massive labeled datasets.
- Improved model accuracy: When labeled data is scarce, SSL often outperforms purely supervised models.
- Scalability: With so much unlabeled data being generated daily (think of all those images, emails, or transactions), SSL provides a practical way to put that data to use.
- Works well with natural datasets: SSL is highly effective for text, images, speech, and other real-world data formats.
Advantages and Disadvantages of Semi-Supervised Learning
Advantages of Semi-Supervised Learning
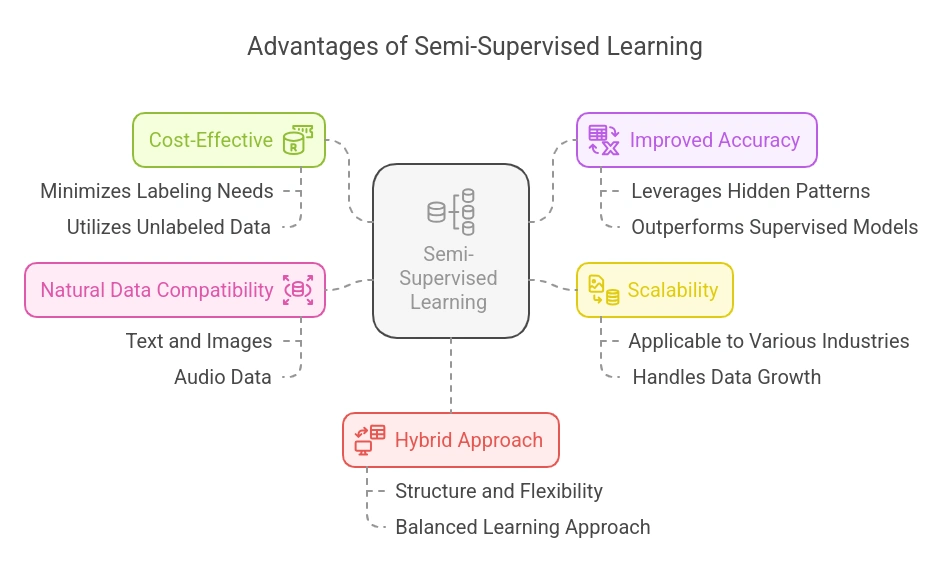
- Cost-Effective: Labeling large datasets is expensive and time-consuming. Semi-supervised learning minimizes this need by making the most out of small labeled datasets combined with vast amounts of unlabeled data.
- Improved Accuracy with Less Data: When labeled data is scarce, SSL often achieves better accuracy than purely supervised models by leveraging hidden patterns in the unlabeled data.
- Scalability: SSL is highly scalable, especially in industries generating large volumes of raw, unlabeled data like social media, e-commerce, and healthcare.
- Works Well with Natural Data: SSL algorithms thrive in complex real-world datasets like text, images, and audio, where labeling every sample is impractical.
- Combines the Best of Both Worlds: By blending supervised and unsupervised techniques, SSL inherits the strengths of both approaches, balancing structure with flexibility.
Disadvantages of Semi-Supervised Learning
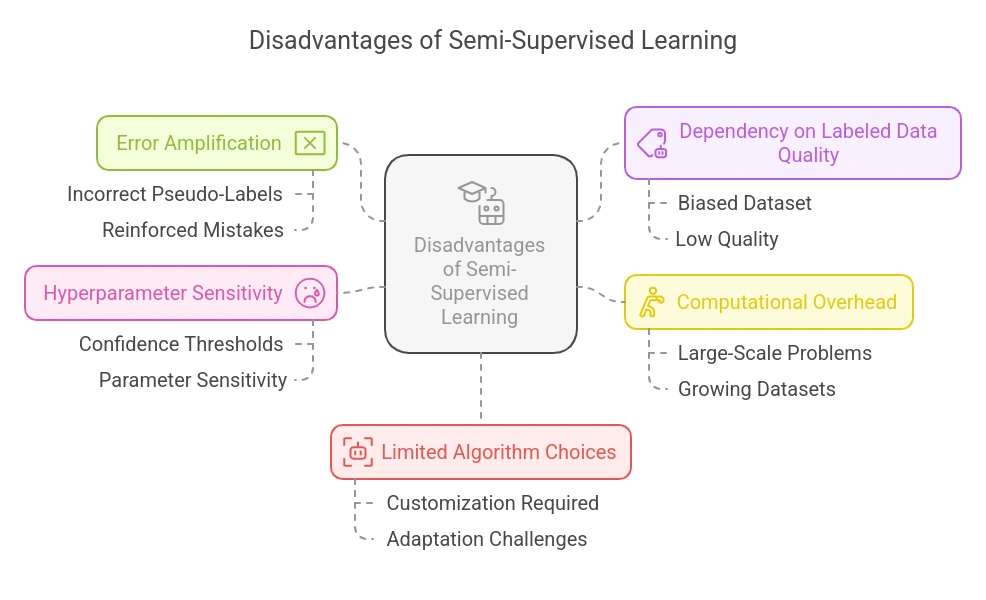
- Error Amplification: Incorrect pseudo-labels can introduce noise and reinforce mistakes, especially if the model confidently labels data incorrectly during early iterations.
- Dependency on Labeled Data Quality: If the small labeled dataset is biased or low quality, the entire model can skew, affecting generalization to new data.
- Computational Overhead: Repeated training cycles on growing datasets (labeled + pseudo-labeled) can become computationally expensive, particularly for large-scale problems.
- Hyperparameter Sensitivity: SSL models can be sensitive to parameters like confidence thresholds, which control what unlabeled data gets pseudo-labeled and reused in training.
- Limited Algorithm Choices: Not all machine learning algorithms are easily adaptable to semi-supervised learning, and some require significant customization.
Real-World Applications of Semi-Supervised Learning
Semi-supervised learning is not just theoretical. It’s actively used across industries:
| Industry | Use Case |
| Healthcare | Diagnosing rare diseases with few examples |
| E-commerce | Product categorization and recommendation |
| Cybersecurity | Detecting new types of malware |
| Natural Language Processing | Language translation and sentiment analysis |
| Autonomous Vehicles | Object recognition with limited labeled images |
Popular Semi-Supervised Learning Algorithms
Some widely used algorithms include:
- Self-training: The model labels the unlabeled data and retrains itself.
- Co-training: Two models are trained on different feature sets and help label each other’s data.
- Graph-based methods: Represent data as a graph and spread labels through connected nodes.
- Generative models: Such as Semi-Supervised GANs (Generative Adversarial Networks).
Challenges of Semi-Supervised Learning
Despite its potential, semi-supervised learning comes with challenges:
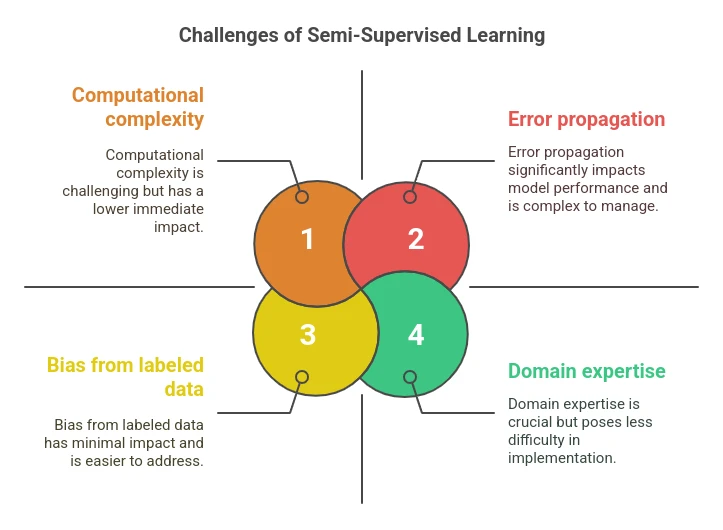
- Error propagation: Incorrect pseudo-labels can degrade model performance.
- Bias from labeled data: A small, unbalanced labeled dataset might skew the entire model.
- Computational complexity: Handling large datasets with iterative retraining can get expensive.
- Domain expertise: Even the initial labeled data must be high-quality to avoid compounding mistakes.
Future of Semi-Supervised Learning
With the explosion of data and the rising costs of data labeling, SSL is becoming more important than ever. As algorithms become more sophisticated, semi-supervised learning will play a central role in areas like:
- Medical diagnostics
- Personalized marketing
- Speech recognition
- Fraud detection
Moreover, it complements other learning paradigms like active learning and transfer learning, pushing the boundaries of what machines can achieve with minimal human intervention.
Want to build a successful career in AI & ML?
Enroll in this AI & ML program to gain expertise in cutting-edge technologies like Generative AI, MLOps, Supervised & Unsupervised Learning, and more. With hands-on projects and dedicated career support, earn certificates and start your AI journey today!
Frequently Asked Questions(FAQ’s)
1. How do you decide the ratio of labeled to unlabeled data in semi-supervised learning?
There’s no one-size-fits-all ratio, but in practice, models often perform well when the labeled data is just enough to guide initial learning—sometimes as little as 1-10% of the total dataset. The ideal ratio depends on the problem complexity, model type, and quality of the labeled data.
2. Is semi-supervised learning suitable for real-time systems?
Semi-supervised learning can work for real-time systems, but it’s more challenging because pseudo-labeling and retraining steps can be computationally intensive. For real-time applications, lightweight semi-supervised techniques or incremental learning strategies are preferred.
3. How is the quality of pseudo-labels verified in semi-supervised learning?
Pseudo-label quality is typically evaluated using confidence thresholds. Only predictions with high confidence scores are added back into training to minimize the risk of error propagation. Some models also use human validation at key stages.
4. Can semi-supervised learning handle noisy data?
SSL can handle some noise, but if both labeled and unlabeled datasets are noisy, the risk of spreading errors increases. Techniques like noise filtering, robust loss functions, and validation loops are commonly used to mitigate this.
5. How does semi-supervised learning compare with active learning?
While semi-supervised learning automatically utilizes unlabeled data with minimal human involvement, active learning selects the most informative data points and actively queries a human for labels. Both approaches aim to reduce labeling costs but differ in methodology—sometimes they are even combined for better results.





