


Have you ever wondered how search engines understand your queries, even when you use different word forms? Or how chatbots comprehend and respond accurately, despite variations in language?
The answer lies in Natural Language Processing (NLP), a fascinating branch of artificial intelligence that enables machines to understand and process human language.
One of the key techniques in NLP is lemmatization, which refines text processing by reducing words to their base or dictionary form. Unlike simple word truncation, lemmatization takes context and meaning into account, ensuring more accurate language interpretation.
Whether it’s enhancing search results, improving chatbot interactions, or aiding text analysis, lemmatization plays a crucial role in multiple applications.
In this article, we’ll explore what lemmatization is, how it differs from stemming, its importance in NLP, and how you can implement it in Python. Let’s dive in!
What is Lemmatization?
Lemmatization is the process of converting a word to its base form (lemma) while considering its context and meaning. Unlike stemming, which simply removes suffixes to generate root words, lemmatization ensures that the transformed word is a valid dictionary entry. This makes lemmatization more accurate for text processing.
For example:
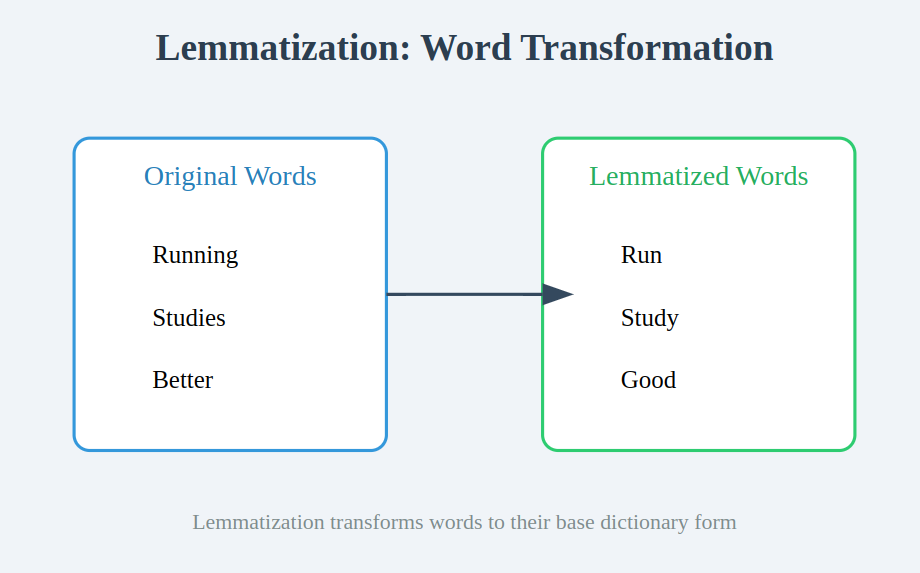
- Running → Run
- Studies → Study
- Better → Good (Lemmatization considers meaning, unlike stemming)
Also Read: What is Stemming in NLP?
How Lemmatization Works
Lemmatization typically involves:
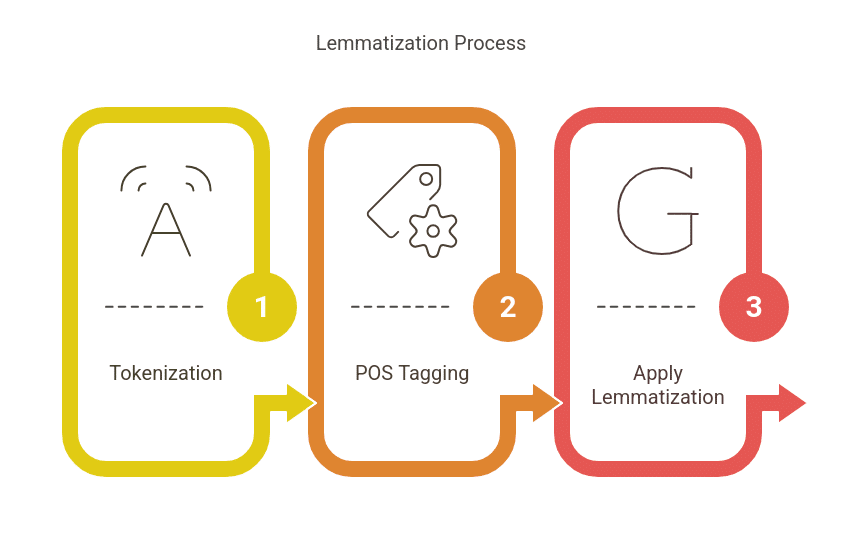
- Tokenization: Splitting text into words.
- Example: Sentence: “The cats are playing in the garden.”
- After tokenization: [‘The’, ‘cats’, ‘are’, ‘playing’, ‘in’, ‘the’, ‘garden’]
- Part-of-Speech (POS) Tagging: Identifying a word’s role (noun, verb, adjective, etc.).
- Example: cats (noun), are (verb), playing (verb), garden (noun)
- POS tagging helps distinguish between words with multiple forms, such as “running” (verb) vs. “running” (adjective, as in “running water”).
- Applying Lemmatization Rules: Converting words into their base form using a lexical database.
- Example:
- playing → play
- cats → cat
- better → good
- Without POS tagging, “playing” might not be lemmatized correctly. POS tagging ensures that “playing” is correctly transformed into “play” as a verb.
- Example:
Example 1: Standard Verb Lemmatization
Consider a sentence: “She was running and had studied all night.”
- Without lemmatization: [‘was’, ‘running’, ‘had’, ‘studied’, ‘all’, ‘night’]
- With lemmatization: [‘be’, ‘run’, ‘have’, ‘study’, ‘all’, ‘night’]
- Here, “was” is converted to “be”, “running” to “run”, and “studied” to “study”, ensuring the base forms are recognized.
Example 2: Adjective Lemmatization
Consider: “This is the best solution to a better problem.”
- Without lemmatization: [‘best’, ‘solution’, ‘better’, ‘problem’]
- With lemmatization: [‘good’, ‘solution’, ‘good’, ‘problem’]
- Here, “best” and “better” are reduced to their base form “good” for accurate meaning representation.
Why is Lemmatization Important in NLP?
Lemmatization plays a key role in improving text normalization and understanding. Its significance includes:
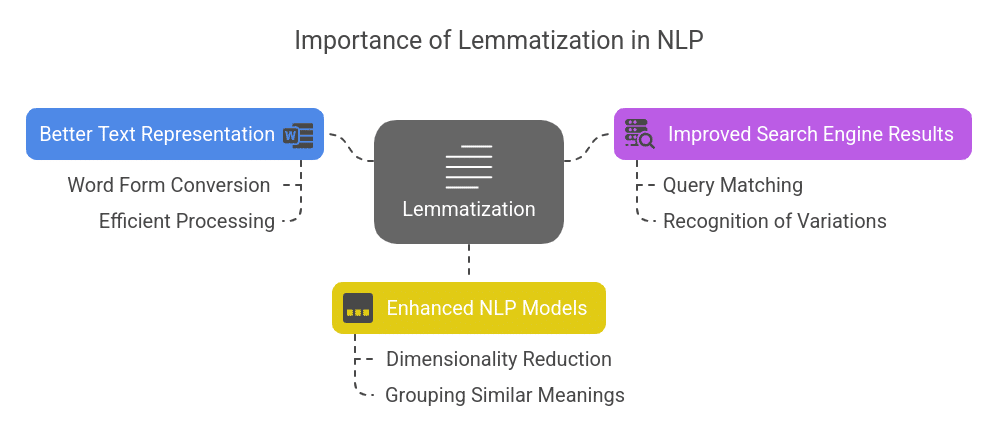
- Better Text Representation: Converts different word forms into a single form for efficient processing.
- Improved Search Engine Results: Helps search engines match queries with relevant content by recognizing different word variations.
- Enhanced NLP Models: Reduces dimensionality in machine learning and NLP tasks by grouping words with similar meanings.
Learn how Text Summarization in Python works and explore techniques like extractive and abstractive summarization to condense large texts efficiently.
Lemmatization vs. Stemming
Both lemmatization and stemming aim to reduce words to their base forms, but they differ in approach and accuracy:
| Feature | Lemmatization | Stemming |
| Approach | Uses linguistic knowledge and context | Uses simple truncation rules |
| Accuracy | High (produces dictionary words) | Lower (may create non-existent words) |
| Processing Speed | Slower due to linguistic analysis | Faster but less accurate |

Implementing Lemmatization in Python
Python provides libraries like NLTK and spaCy for lemmatization.
Using NLTK:
from nltk.stem import WordNetLemmatizer
from nltk.corpus import wordnet
import nltk
nltk.download('wordnet')
nltk.download('omw-1.4')
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("running", pos="v")) # Output: run
Using spaCy:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("running studies better")
print([token.lemma_ for token in doc]) # Output: ['run', 'study', 'good']
Applications of Lemmatization
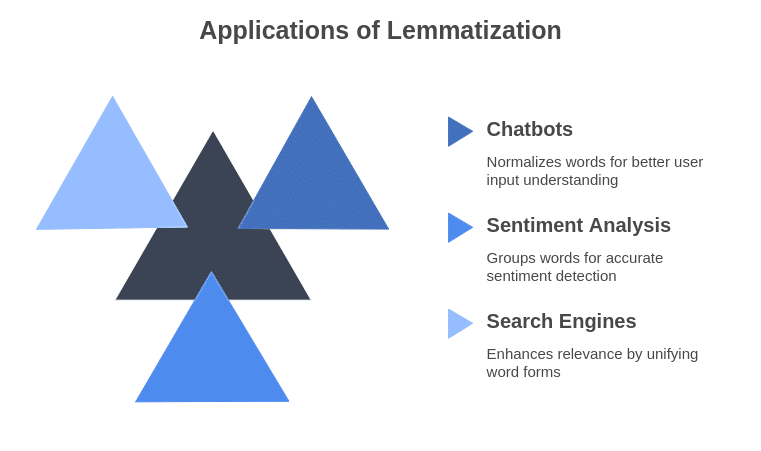
- Chatbots & Virtual Assistants: Understands user inputs better by normalizing words.
- Sentiment Analysis: Groups words with similar meanings for better sentiment detection.
- Search Engines: Enhances search relevance by treating different word forms as the same entity.
Suggested: Free NLP Courses
Challenges of Lemmatization
- Computational Cost: Slower than stemming due to linguistic processing.
- POS Tagging Dependency: Requires correct tagging to generate accurate results.
- Ambiguity: Some words have multiple valid lemmas based on context.
Future Trends in Lemmatization
With advancements in AI and NLP , lemmatization is evolving with:
- Deep Learning-Based Lemmatization: Using transformer models like BERT for context-aware lemmatization.
- Multilingual Lemmatization: Supporting multiple languages for global NLP applications.
- Integration with Large Language Models (LLMs): Enhancing accuracy in conversational AI and text analysis.
Conclusion
Lemmatization is an essential NLP technique that refines text processing by reducing words to their dictionary forms. It improves the accuracy of NLP applications, from search engines to chatbots. While it comes with challenges, its future looks promising with AI-driven improvements.
By leveraging lemmatization effectively, businesses and developers can enhance text analysis and build more intelligent NLP solutions.
Master NLP and lemmatization techniques as part of the PG Program in Artificial Intelligence & Machine Learning.
This program dives deep into AI applications, including Natural Language Processing and Generative AI, helping you build real-world AI solutions. Enroll today and take advantage of expert-led training and hands-on projects.
Frequently Asked Questions(FAQ’s)
What is the difference between lemmatization and tokenization in NLP?
Tokenization breaks text into individual words or phrases, whereas lemmatization converts words into their base form for meaningful language processing.
How does lemmatization improve text classification in machine learning?
Lemmatization reduces word variations, helping machine learning models identify patterns and improve classification accuracy by normalizing text input.
Can lemmatization be applied to multiple languages?
Yes, modern NLP libraries like spaCy and Stanza support multilingual lemmatization, making it useful for diverse linguistic applications.
Which NLP tasks benefit the most from lemmatization?
Lemmatization enhances search engines, chatbots, sentiment analysis, and text summarization by reducing redundant word forms.
Is lemmatization always better than stemming for NLP applications?
While lemmatization provides more accurate word representations, stemming is faster and may be preferable for tasks that prioritize speed over precision.





