In the rapidly evolving world of deep learning and computer vision, some architectures have left a lasting impact due to their simplicity, effectiveness, and scalability. One such landmark model is VGG, developed by the Visual Geometry Group at the University of Oxford.
If you’re exploring convolutional neural networks (CNNs) or seeking a powerful, well-established model for image recognition, understanding VGG is a must.
In this article, we’ll cover what VGG is, its architecture, advantages, disadvantages, real-world applications, and frequently asked questions to showcase a complete picture of why VGG continues to influence deep learning today.
What is Visual Geometry Group (VGG)?
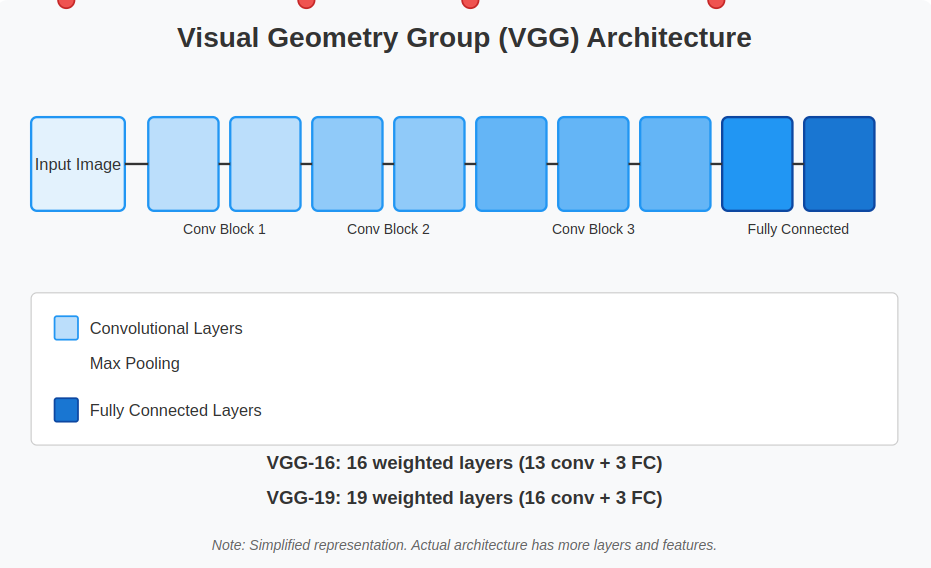
VGG, short for Visual Geometry Group, is a widely used deep convolutional neural networks (CNNs) architecture known for its multiple layers. The term “deep” signifies the large number of layers in the network, with VGG-16 and VGG-19 comprising 16 and 19 convolutional layers, respectively.
VGG has played a significant role in advancing object recognition models and has outperformed many baseline models across various tasks and datasets, including ImageNet.
Despite being developed years ago, it remains one of the most widely used architectures for image recognition due to its effectiveness and structured design.
Why is VGG Important?
VGG’s success lies in its simplicity and effectiveness:
- It uses only 3×3 convolutional layers stacked on top of each other.
- It increases depth to improve accuracy.
- It is highly transferable to different vision tasks like object detection, segmentation, and style transfer.
Even though newer architectures like ResNet and EfficientNet have surpassed VGG in efficiency, VGG remains a foundational model in computer vision education and practice.
Suggested: Free Deep Learning Courses
VGG Architecture Explained in Detail
The VGG architecture stands out due to its elegant simplicity and systematic design. The main concept focuses on utilizing small convolutional filters (3×3) and layering them more deeply to capture intricate features from images.
Let’s analyze the structure step by step:
1. Input Layer:
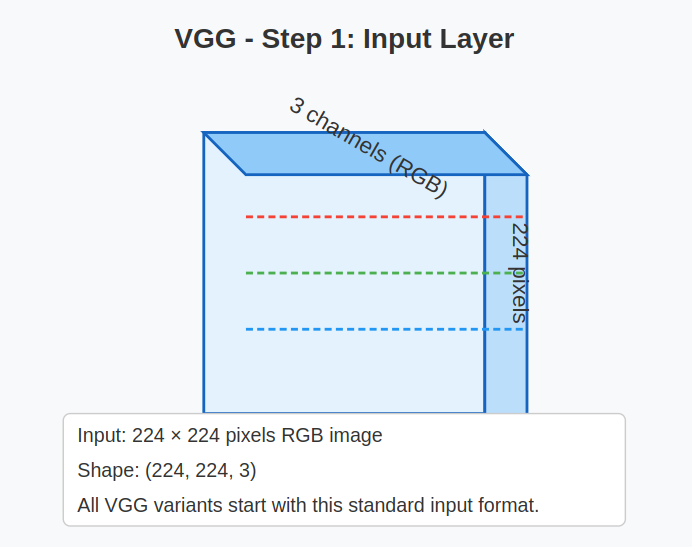
- Input size: VGG is designed to take in fixed-size images of 224 x 224 pixels with 3 color channels (RGB).
Example: Input shape = (224, 224, 3)
2. Convolutional Layers:

- VGG uses multiple convolutional layers with:
- Filter size: 3×3
- Stride: 1
- Padding: ‘Same’ (to preserve spatial resolution)
- The 3×3 kernel captures fine-grained details while stacking layers increases the receptive field.
- Depth increases progressively across the network by adding more filters (starting from 64 and going up to 512).
Why stack multiple 3×3 convolutions?
Stacking two 3×3 convolutions has the same effective receptive field as a single 5×5 convolution but with fewer parameters and more non-linearity.
3. Activation Function:

- After every convolutional layer, VGG applies a ReLU (Rectified Linear Unit) activation.
- This introduces non-linearity, helping the network learn complex patterns efficiently.
Formula: ReLU(x) = max(0, x)
4. Pooling Layers:
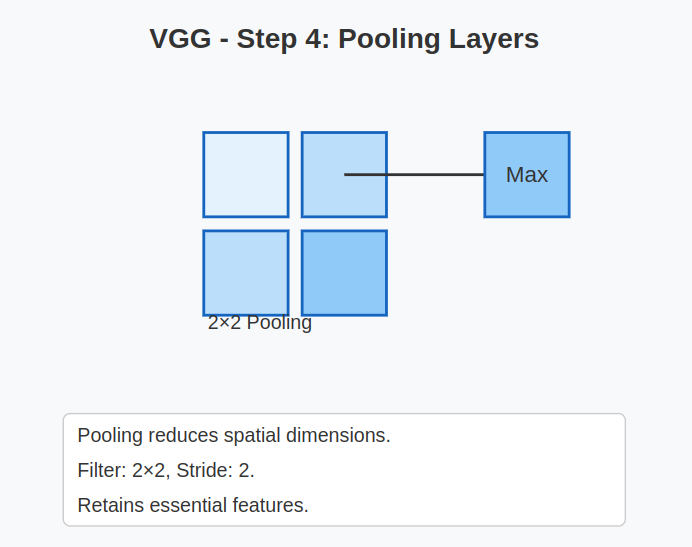
- After every few convolutional blocks, VGG uses a Max Pooling layer.
- Filter size: 2×2
- Stride: 2
- Purpose: To reduce the spatial dimensions (height and width) while keeping the most essential features.
- This helps reduce computation and controls overfitting.
5. Fully Connected (Dense) Layers:
- After the convolution and pooling operations, the output is flattened into a 1D vector.
- VGG typically uses two or three fully connected layers:
- First two FC layers: 4096 neurons each
- Final FC layer: Number of neurons equal to the number of output classes (e.g., 1000 for ImageNet).
These layers serve as a classifier on top of the extracted features.
6. Output Layer:
- The final layer uses the Softmax activation function to output probabilities for each class.
- Example:
- For ImageNet, it predicts over 1,000 different object categories.
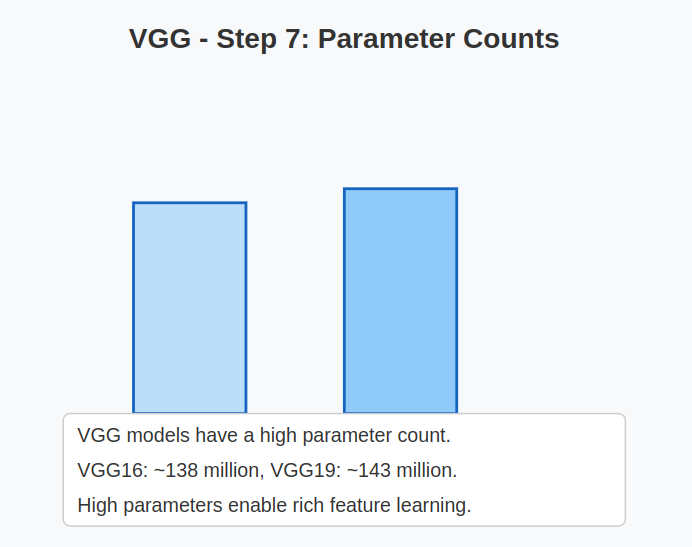
7. Parameter Counts:
One of the major characteristics of VGG is its large number of parameters, especially due to the fully connected layers.
| Model | Total Parameters | Layers |
| VGG16 | ~138 million | 16 |
| VGG19 | ~143 million | 19 |
This makes VGG computationally expensive but also highly capable of learning rich feature representations.
VGG16 Architecture Breakdown (Example):
| Layer Type | Output Size | Filters/Neurons |
| Input | (224, 224, 3) | – |
| Conv3-64 x2 | (224, 224, 64) | 64 |
| Max Pool | (112, 112, 64) | – |
| Conv3-128 x2 | (112, 112, 128) | 128 |
| Max Pool | (56, 56, 128) | – |
| Conv3-256 x3 | (56, 56, 256) | 256 |
| Max Pool | (28, 28, 256) | – |
| Conv3-512 x3 | (28, 28, 512) | 512 |
| Max Pool | (14, 14, 512) | – |
| Conv3-512 x3 | (14, 14, 512) | 512 |
| Max Pool | (7, 7, 512) | – |
| Flatten | (25088 | – |
| Fully Connected | (4096) | 4096 |
| Fully Connected | (4096) | 4096 |
| Fully Connected | (1000) | 1000 |
| Softmax Output | (1000) | – |
Why is VGG Architecture Special?
- Modularity: It repeats the same block structure, making it easy to scale and modify.
- Feature Hierarchy: Lower layers learn simple features (edges, colors), while deeper layers learn complex patterns (shapes, objects).
- Transferability: The features learned by VGG work well on different datasets, which is why pre-trained VGG models are heavily used in transfer learning.
Advantages of VGG
- Simplicity: VGG’s uniform architecture (stacked 3×3 filters) makes it easier to understand and implement.
- Transfer Learning Friendly: Pre-trained VGG models are widely used for transfer learning, saving time and resources on new projects.
- Strong Baseline: Despite being older, VGG serves as a robust baseline in many research experiments and applications.
- Consistent Performance: VGG performs reliably on a wide range of visual tasks beyond image classification.
Disadvantages of VGG
- Large Model Size: VGG requires significant storage (over 500MB), making it less practical for deployment on mobile or edge devices.
- Computationally Heavy: The model has high memory usage and slow inference times due to its depth and number of parameters.
- Outperformed by Modern Architectures: Models like ResNet and MobileNet achieve similar or better accuracy with fewer parameters and faster processing.
Get familiar with popular Machine Learning algorithms.
Real-World Applications of VGG
| Field | Application Example |
| Healthcare | Medical image analysis and diagnostics |
| Automotive | Object recognition in autonomous vehicles |
| Security | Face detection and surveillance systems |
| Retail | Visual product search and recommendation |
| Art & Design | Style transfer and image enhancement |
Popular VGG-Based Projects
- Image Style Transfer – Using VGG layers to blend the style of one image with the content of another.
- Feature Extraction – Leveraging VGG as a feature extractor in complex pipelines.
- Object Detection – Combined with region proposal networks in tasks like Faster R-CNN.
Discover how a Recurrent Neural Network (RNN) works and why it’s widely used for language modeling and time-series predictions.
Conclusion
The VGG architecture is a fundamental part of deep learning history. VGG, with its refined simplicity and demonstrated effectiveness, is crucial knowledge for anyone exploring computer vision.
Whether you’re developing a research project, utilizing transfer learning, or trying out style transfer, VGG offers a robust base to begin.
Build a Career in Machine Learning
Our Data Science and Machine Learning program teaches you core neural network techniques that power computer vision.
Learn from MIT faculty through hands-on projects and personalized mentorship to build practical, data-driven solutions. Enroll now to elevate your career in AI and real-world innovation.
Frequently Asked Questions
1. Why are 3×3 filters used in VGG?
VGG uses 3×3 filters because they capture small details while allowing deeper networks with fewer parameters compared to larger filters like 5×5 or 7×7.
2. How does VGG compare to ResNet?
VGG is simpler but heavier. ResNet uses residual connections to train deeper networks with better performance and efficiency.
3. Can VGG be used for non-image data?
VGG is optimized for images, but its convolutional principles can sometimes be adapted to sequential data like audio or video.
4. How do VGG16 and VGG19 differ?
The main difference lies in depth—VGG19 has three more convolutional layers than VGG16, which slightly improves accuracy but increases computation.
5. Is VGG still relevant today?
Yes, especially in education, research baselines, and transfer learning, though modern architectures may outperform it in production environments.