


What is Tokenization?
Tokenisation is the process of breaking up a given text into units called tokens. Tokens can be individual words, phrases or even whole sentences. In the process of tokenization, some characters like punctuation marks may be discarded. The tokens usually become the input for the processes like parsing and text mining.
Almost every Natural language processing task uses some sort of tokenisation technique. It is vital to understand the pattern in the text to achieve tasks like sentiment analysis, named entity recognition also known as NER, POS tagging, Text classification, intelligent chatbot, language translation, text summarisation and many more.
These tokens are very useful for finding such patterns as well as is considered as a base step for stemming and lemmatization. Stemming and Lemmatization both generate the root form of the inflected words obtained from tokenisation.
Tokenisation Techniques (Optional)
In this section, we are going to explore some of the tokenisation techniques. If you are only concerned about implementing tokenisation, you can skip ahead to the next sections
White space tokenisation:
Perhaps this is one of the simplest technique to tokenize a sentence or paragraph into words. In this technique, the input sentence is broken apart every time a white-space is encountered. Although this is a fast and easy way to implement tokenisation, this technique only works in languages where meaningful units are separated by spaces e.g English. But for words such as living room, full moon, real estate, coffee table, this method might work accurately.
Dictionary based tokenisation:
This is a much more advanced method than white space tokeniser. We find tokens from the sentences that are already in the dictionary. This approach needs specific guidance if the tokens in the sentence aren’t in the dictionary For languages without spaces between words, there is an additional step of word segmentation where we find sequences of characters that have a certain meaning.
Subword Tokenisation:
This is a collection of approaches usually using unsupervised machine learning techniques. This method finds short sequences of characters that are often used together and assigns each of them to be a separate token. As this is an unsupervised method, sometimes we may encounter tokens that have actually no real meaning.
These were some of the techniques that may have given you a brief overview of technicality behind tokenisation. Now in the next section, we will see how we can use some libraries and frameworks to do tokenisation for us.
Tokenisation with NLTK
NLTK is a standard python library with prebuilt functions and utilities for the ease of use and implementation. It is one of the most used libraries for natural language processing and computational linguistics.
The tasks such as tokenisation, stemming, lemmatisation, chunking and many more can be implemented in just one line using NLTK. Now let us see some of the popular tokenisers used for tokenising text into sentences or words available on NLTK.
First install NLTK in your PC, if not already installed. To install it go to the command prompt and type.
pip install nltk
Next, go to the editor and run these lines of code
import nltk
nltk.download(‘all’)
Tokenising into sentences: Some of the tokenisers that can split a paragraph into sentences are given below. The results obtained from each may be a little different, thus you must choose an appropriate tokeniser that’ll work best for you. Now let us take a look at some examples taken from NLTK documentation.
sent_tokenize
import nltk
from nltk import sent_tokenize
text = '''Hello everyone. welcome to the Great Learning.
Mr. Smith("He is instructor") and Johann S. Baech
(He is also an instructor.) are waiting for you'''
sent_tokenize(text) Output:

Actually, sent_tokenize is a wrapper function that calls tokenize by the Punkt Sentence Tokenizer. This tokeniser divides a text into a list of sentences by using an unsupervised algorithm to build a model for abbreviation words, collocations, and words that start sentences. It must be trained on a large collection of plaintext in the target language before it can be used., here is the code in NLTK:
text = '''Hello everyone. welcome to the Great Learning.Mr. Smith("He is instructor") and Johann S. Baech (He is also an instructor.) are waiting for you'''
sent_detector = nltk.data.load('tokenizers/punkt/english.pickle')
print("'\n-----\n'".join(sent_detector.tokenize(text.strip())))Output:

As we can see the output is the same. Also, the parameter realign_boundaries can change the output in the following way if set false
text = '''Hello everyone. welcome to the Great Learning.Mr. Smith("He is instructor") and Johann S. Baech (He is also an instructor.) are waiting for you'''
sent_detector = nltk.data.load('tokenizers/punkt/english.pickle')
print("'\n-----\n'".join(sent_detector.tokenize(text.strip(),realign_boundaries=False)))Output:

BlanklineTokenizer: This tokeniser separates the sentences when there is a blank line between them. We can use this tokeniser to extract paragraphs from a large corpus of text
from nltk.tokenize import BlanklineTokenizer
text = '''Hello everyone. welcome to the Great Learning.
Mr. Smith("He is instructor") and Johann S. Baech
(He is also an instructor.) are waiting for you'''
BlanklineTokenizer().tokenize(text)Output:
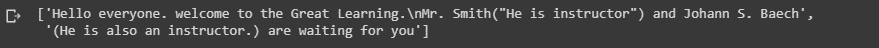
Now here are few methods for tokenising a text into words
word_tokenize
from nltk import word_tokenize
text = '''Hello everyone . welcome to the Great Learning .
Mr. Smith("He isn't an instructor") and Johann S. Baech
(He is an instructor.) are waiting for you . They'll join you soon.'''
for t in sent_tokenize(text):
x=word_tokenize(t)
print(x)Output:

word_tokenize is a wrapper function that calls tokenize by the Treebank tokenizer. The Treebank tokenizer uses regular expressions to tokenize text as in Penn Treebank. Here is the code for Treebank tokenizer
from nltk.tokenize import TreebankWordTokenizer
for t in sent_tokenize(text):
x=TreebankWordTokenizer().tokenize(t)
print(x)Output:

WhitespaceTokenizer: As the name suggests, this tokeniser splits the text whenever it encounters a space.
from nltk.tokenize import WhitespaceTokenizer
for t in sent_tokenize(text):
x=WhitespaceTokenizer().tokenize(t)
print(x)Output:

wordpunct_tokenize:wordpunct_tokenize is based on a simple regexp tokenization.Basically it uses the regular expression ” \w+|[^\w\s]+” to split the input.
from nltk.tokenize import wordpunct_tokenize
for t in sent_tokenize(text):
x=wordpunct_tokenize(t)
print(x)Output:

Multi-Word Expression Tokenizer(MWETokenizer): A MWETokenizer takes a string and merges multi-word expressions into single tokens, using a lexicon of MWEs.As you may have noticed in the above examples, Great learning being a single entity is separated into two tokens. We can avoid this and also merge some other expressions such as Johann S. Baech and a lot into single tokens
from nltk.tokenize import MWETokenizer
text = '''Hello everyone . welcome to the Great Learning .
Mr. Smith("He isn't an instructor") and Johann S. Baech
(He is an instructor.) are waiting for you . They'll join you soon.
Hope you enjoy a lot'''
tokenizer = MWETokenizer([('Great', 'Learning'), ('Johann', 'S.', 'Baech'), ('a', 'lot')],separator=' ')
for t in sent_tokenize(text):
x=tokenizer.tokenize(t.split())
print(x)Output:

Tweet Tokenizer: Tweet tokeniser is a special tokeniser which works best for tweets or in general social media comments and posts. It can preserve the emojis and also come with many handy options. Few of the examples are
from nltk.tokenize import TweetTokenizer
tknzr = TweetTokenizer(strip_handles=True)
tweet= " @GL : Great Learning is way tooo coool #AI: :-) :-P <3 . Here are some arrows < > -> <--"
for t in sent_tokenize(tweet):
x=tknzr.tokenize(t)
print(x)Output:

Here we are able to remove handles from tokens. Also if you may have noticed #AI is not divided into separate tokens which is exactly what we want when tokenising tweets.
RegexpTokenizer: This tokeniser splits a string into substrings using a regular expression. For example, the following tokenizer forms tokens out of alphabetic sequences, money expressions, and any other non-whitespace sequences:
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('\w+|\$[\d\.]+|\S+')
for t in sent_tokenize(text):
x=tokenizer.tokenize(t)
print(x)Output:

There are many more tokenisers available in NLTK library that you can find in their official documentation.
Tokenising with TextBlob
TextBlob is a Python library for processing textual data. Using its simple API we can easily perform many common natural language processing (NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more. So now let us see how TextBlob performs when it comes to tokenisation.
To install it in your PC, go the terminal and run this command
pip install textblob
Here is a code to tokenize a text into sentences and words
from textblob import TextBlob
text = '''Hello everyone . welcome to the Great Learning .
Mr. Smith("He isn't an instructor") and Johann S. Baech
(He is an instructor.) are waiting for you . They'll join you soon.
Hope you enjoy a lot. @GL : Great Learning is way tooo coool #AI: :-) :-P <3 . Here are some arrows < > -> <--'''
# create a TextBlob object
blob_object = TextBlob(text)
# tokenize paragraph into words.
print(" Word Tokenize :\n", blob_object.words)
# tokenize paragraph into sentences.
print("\n Sentence Tokenize :\n", blob_object.sentences) Output:
Word Tokenize :
['Hello', 'everyone', 'welcome', 'to', 'the', 'Great', 'Learning', 'Mr', 'Smith', 'He', 'is', "n't", 'an', 'instructor', 'and', 'Johann', 'S', 'Baech', 'He', 'is', 'an', 'instructor', 'are', 'waiting', 'for', 'you', 'They', "'ll", 'join', 'you', 'soon', 'Hope', 'you', 'enjoy', 'a', 'lot', 'GL', 'Great', 'Learning', 'is', 'way', 'tooo', 'coool', 'AI', 'P', '3', 'Here', 'are', 'some', 'arrows']
Sentence Tokenize :
[Sentence("Hello everyone ."), Sentence("welcome to the Great Learning ."), Sentence("Mr. Smith("He isn't an instructor") and Johann S. Baech
(He is an instructor.)"), Sentence("are waiting for you ."), Sentence("They'll join you soon."), Sentence("Hope you enjoy a lot."), Sentence("@GL : Great Learning is way tooo coool #AI: :-) :-P <3 ."), Sentence("Here are some arrows < > -> <--")]As you might have noticed, TextBlob removes punctuation including emojis automatically from tokens. But we do not get as much customisation options as we get in NLTK
This brings us to the end of this article where we have learned about tokenisation and various ways to implement it.
If you wish to learn more about Python and the concepts of Machine Learning, upskill with Great Learning’s PG Program Artificial Intelligence and Machine Learning.





