
Supervised Machine Learning Models with associated learning algorithms that analyze data for classification and regression analysis are known as Support Vector Regression. SVR is built based on the concept of Support Vector Machine or SVM. It is one among the popular Machine Learning models that can be used in classification problems or assigning classes when the data is not linearly separable.
Contributed by: Vijay Krishnan MR
Introduction to Support Vector Regression
Before we dive into the topic of Support vector Regression (SVR), it is important to know the concept of SVM based on which SVR is built.
It is one of the classic examples of supervised Machine learning technique. We could say it’s one of the more powerful models which can be used in classification problems or assigning classes when the data is not linearly separable. I would give a classic kitchen example; I am sure most of us love chips? Of course, I do. I wanted to make homemade chips. I bought potatoes from the vegetable market and hit my kitchen. All I did was follow a YouTube video. I started slicing the potatoes in the hot oil, the result was a disaster, and I ended up getting chips which were dark brown/black.
What was wrong here? I had purchased potatoes, followed the procedure shown in the video and also maintained the right temperature of the oil, did I miss something? When I did my research by asking experts, I found that I did miss the trick, I had chosen potatoes with higher starch content instead of lower ones. All the potatoes looked the same for me, this is where the years and years of training comes into the picture, the experts had well-trained eyes on how to choose potatoes with lower starch. It has some specific features such as these potatoes would look fresh and will have some additional skin which could be peeled from our fingernails, and they look muddy.
With the chips example, I was only trying to tell you about the nonlinear dataset. While many classifiers exist that can classify linearly separable data like logistic regression or linear regression, SVMs can handle highly non-linear data using an amazing technique called kernel trick. It implicitly maps the input vectors to higher dimensional (adds more dimensions) feature spaces by the transformation which rearranges the dataset in such a way that it is linearly solvable.
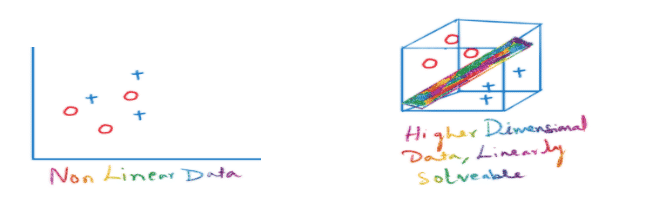
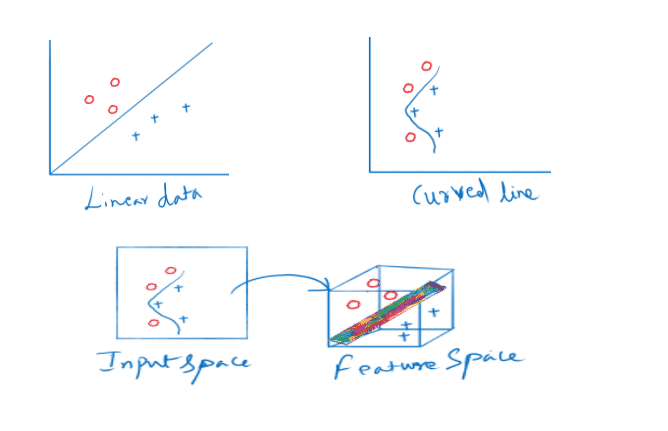
In short, a kernel is a function which places a low dimensional plane to a higher dimensional space where it can be segmented using a plane. In other words, it transforms linearly inseparable data to separable data by adding more dimensions to it.
There are three kernels which SVM uses the most
- Linear kernel: Dot product between two given observations
- Polynomial kernel: This allows curved lines in the input space
- Radial Basis Function (RBF): It creates complex regions within the feature space
In general, regression problems involve the task of deriving a mapping function which would approximate from input variables to a continuous output variable.
Support Vector Regression uses the same principle of Support Vector Machines. In other words, the approach of using SVMs to solve regression problems is called Support Vector Regression or SVR.
Read more on Difference between Data Science, Machine Learning & AI
Now let us look at the classic example of the Boston House Price dataset. It has got 14 columns, where we have one target variable and 13 independent variables with 506 rows/ records. The approach will be to use SVR and use all the three Kernels and then compare the error metric and choose the model with the least error and then come up with the observation on the dataset whether its linear or not. The dataset is available at Boston Housing Dataset. Though the dataset looks simple and we could do a traditional regression we want to see if the dataset is linear or not and how SVR performs with various kernels, here we will be focusing on MAE & RMSE only, lower the value better is the model. You can look at the code which is available in my GitHub repository that is mentioned in the reference section.
Based on the above results we could say that the dataset is non- linear and Support Vector Regression (SVR)performs better than traditional Regression however there is a caveat, it will perform well with non-linear kernels in SVR. In our case, SVR performs the least in Linear kernel, performs well to moderate when Polynomial kernel is used and performs better when we use the RBF (or Gaussian) Kernel. Maybe I wouldn’t have left with burnt potato chips had I used SVR while selecting the potatoes as they were non-linear though they looked very similar. I hope this article was useful in understanding the basics of SVM and SVR, and when we need to use SVR.
If you found this helpful and wish to learn more such concepts, join Great Learning Academy's free online courses today.
Our Machine Learning Courses
Explore our Machine Learning and AI courses, designed for comprehensive learning and skill development.
| Program Name | Duration |
|---|---|
| MIT No code AI and Machine Learning Course | 12 Weeks |
| MIT Data Science and Machine Learning Course | 12 Weeks |
| Data Science and Machine Learning Course | 12 Weeks |








