


Neural networks have revolutionized deep learning, enabling applications ranging from computer vision to natural language processing (NLP). However, traditional feedforward networks struggle with sequential data because they process inputs independently, lacking memory of past events.
Recurrent Neural Networks (RNNs) solve this limitation by introducing a mechanism that retains information across time steps, making them ideal for processing sequential data such as text, speech, and time series predictions.
What is a Recurrent Neural Network (RNN)?
RNNs are artificial neural networks specifically created to handle sequential data by remembering prior inputs in their internal memory. Unlike feedforward networks, where each input is processed separately, RNNs add a hidden state that permits information to carry over.
Key Concepts:
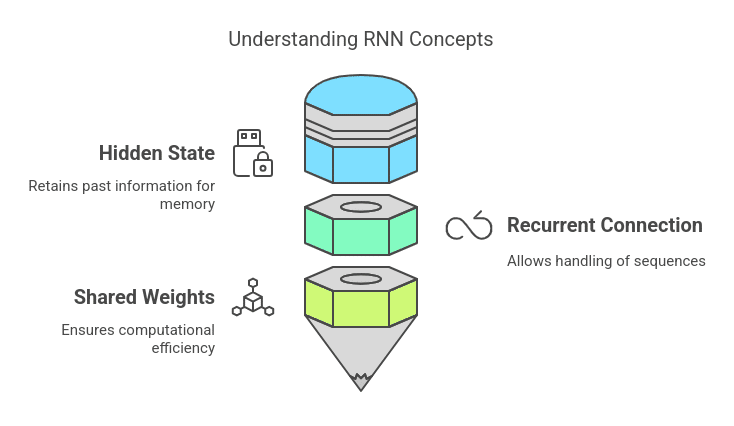
1. Hidden State (h_t):
The hidden state is a vector that serves as the memory of the network. It retains past information and is updated at each time step based on the current input and the previous hidden state.
2. Recurrent Connection:
In contrast to feedforward networks, where signals propagate in one direction (input →, hidden layers → output), RNNs contain loops within their structure. This recurrent linkage allows them to handle sequences taking into account earlier elements.
3. Shared Weights:
The weights applied to each time step remain the same across the sequence, ensuring computational efficiency and reducing the number of parameters to learn.
4. Mathematical Representation:
For a given input sequence, RNNs update the hidden state using:
Equations:
ht = σ(Whht-1 + Wxxt + bh)
yt = σ(Wyht + by)
Where:
- xt = input at time step t
- ht = hidden state at time step t
- Wh, Wx, Wy = weight matrices
- bh, by = biases
- σ = activation function (e.g., ReLU)
Working of Recurrent Neural Networks
RNNs process sequential data step-by-step, updating their hidden state at each time step. This allows them to retain relevant past information and use it for future predictions.
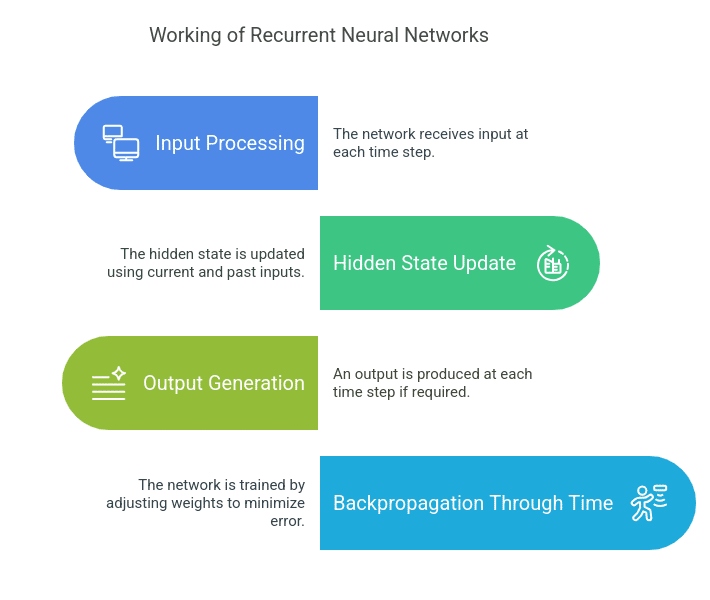
Step-by-Step Explanation:
- Input Processing: The network is given an input during the time step.
- Hidden State Update: The hidden state is computed from the current input and the last hidden state.
- Output Generation: An output is generated at every time step if needed.
- Backpropagation Through Time (BPTT): The network is trained with a variation of gradient descent that unrolls the RNN in time, updating weights to reduce error.
Training Challenges:
- Vanishing Gradient Problem: Gradients shrink exponentially, making it challenging to learn long-range dependencies.
- Exploding Gradient Problem: Gradients grow too large, leading to unstable weight updates.
Types of RNN Architectures
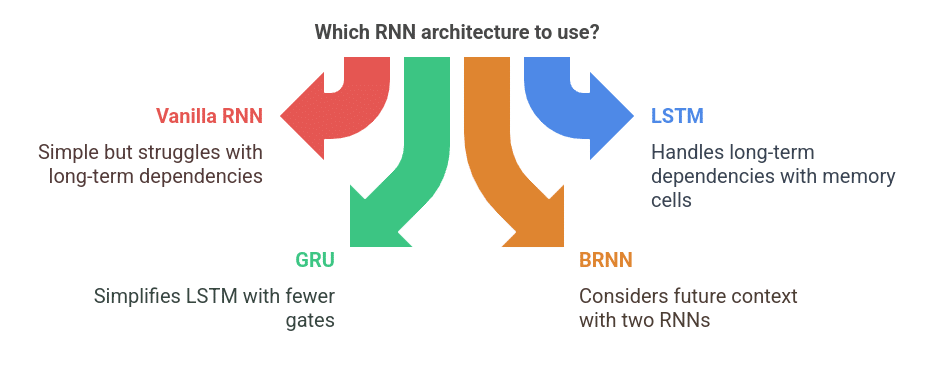
1. Vanilla RNN
The simplest form of RNN is where each unit has a single hidden state. It struggles with long-term dependencies due to the vanishing gradient problem.
2. Long Short-Term Memory (LSTM)
LSTMs were introduced to address the vanishing gradient problem by incorporating memory cells that retain information for long periods.
Key Components:
- Forget Gate: Determines what information to discard from the memory.
- Input Gate: Decides which new information should be added to memory.
- Cell State: Stores the long-term dependencies.
- Output Gate: Controls what information is passed to the next time step.
3. Gated Recurrent Units (GRU)
GRUs simplify LSTMs by combining the forget and input gates into a single update gate.
Key Components:
- Update Gate: Determines how much past information should be retained.
- Reset Gate: This controls how much past information should be forgotten.
4. Bidirectional RNN (BRNN)
- Uses two RNNs: one processes input forward, another backward.
- Useful in NLP tasks where future context is essential.
Applications of RNNs
Here’s a detailed breakdown of the main points covered in the discussion on RNN applications in language modeling:
1. Text Classification
Text classification involves assigning predefined categories to text based on its content. This can include sentiment analysis (e.g., positive or negative reviews), topic classification, author identification, and spam detection.
How RNNs Help:
- Since text data is sequential, RNNs can learn patterns over time, making them effective in understanding the structure and meaning of a sentence.
- Many-to-one RNN architectures process the entire text and then output a classification label.
- Advanced techniques like Convolutional LSTM (C-LSTM) combine CNNs and LSTMs, leveraging CNN’s ability to capture local patterns and LSTMs’ strength in handling long-term dependencies.
- Another innovation, Disconnected RNN (DRNN), controls how much context a model considers, improving performance on classification tasks.
Also Read: What is CNN?
2. Text Summarization
Summarization can be of two types:
- Extractive Summarization: Select key sentences from the text and combine them to form a summary.
- Abstractive Summarization: Generates new sentences that convey the same meaning as the original text.
Extractive Summarization Using RNNs:
- Uses a many-to-one RNN model to classify whether each sentence should be included in the summary.
- Some models, like Xu et al.’s approach, combine CNNs and bidirectional LSTMs to extract sentences and propose compressions for better readability.
Abstractive Summarization Using RNNs:
- Relies on a many-to-many RNN architecture for text generation.
- A significant challenge is grammatical correctness, which has improved with better language models and more powerful computing resources.
- Handling rare words is another challenge; GRU-RNN, with an attention mechanism (Nallapati et al.), introduced a “switching decoder” that either generates a word from the vocabulary or points to a word in the input text.
- Another improvement, Variational Auto-Encoder (VAE)-based RNNs, helps capture latent structures in text to improve the quality of generated summaries.
3. Machine Translation
Machine Translation (MT) is an automatic text conversion from one language to another.
How RNNs Help:
- Traditional RNNs struggle with long input sequences, but encoder-decoder architectures solve this by compressing the input into a vector representation before decoding it into another language.
- Attention Mechanisms further improved performance by helping the model focus on relevant words in the input while generating each word in the output.
- Global Attention: Considers all words in the input when predicting each word in the output.
- Local Attention: Focuses on only a small input section, making the model more efficient.
4. Image-to-Text Translation
This involves generating descriptive captions for images using deep-learning models.
How RNNs Help:
- CNNs first extract visual features from an image. These features are then passed to an RNN-based language model, which generates a textual description.
- Attention-based RNN models (Xu et al.) improve performance by dynamically selecting relevant image regions while generating each word.
- Advanced models also integrate external text sources (e.g., news articles) to provide richer captions.
5. Chatbots for Mental Health and Autism Spectrum Disorder (ASD)
Chatbots are AI-driven conversational agents in areas like customer service and personal assistance. Recently, they have been used in mental health support and ASD intervention.
How RNNs Help:
- Conversations require maintaining context across multiple turns, which RNNs handle well through their sequential memory structure.
- Bi-LSTM models have been particularly effective in chatbot applications.
- Mental Health Chatbots: Rakib et al. built a Bi-LSTM-based chatbot that responds empathetically to patients with mental illnesses.
- ASD Chatbots: Zhong et al. developed a Bi-LSTM chatbot trained on child interactions to assist children with ASD in learning social communication.
Challenges of RNNs
1. Vanishing and Exploding Gradients
- When backpropagating, small gradient values get even smaller, leading to ineffective learning.
- Conversely, large gradients grow uncontrollably, making optimization difficult.
2. Sequential Processing Bottleneck
- Unlike Transformers, RNNs cannot be parallelized efficiently, making training slow.
3. Short-Term Memory Issue
- Standard RNNs struggle with long-range dependencies, making them ineffective for long text sequences.
Improvements & Alternatives to RNNs
1. LSTMs & GRUs: Address vanishing gradient issues by incorporating gates.
2. Attention Mechanisms: Allow models to focus on relevant parts of sequences instead of processing everything equally.
3. Transformer Models (e.g., BERT, GPT): Replace recurrence with self-attention, enabling parallel processing and better performance in NLP tasks.
4. CNN-based Sequence Models (e.g., WaveNet): Use convolutional layers instead of recurrence for sequential data processing.
Conclusion
In conclusion, Recurrent Neural Networks (RNNs) are essential tools for sequential data processing, excelling in tasks like text classification, machine translation, and image-to-text translation.
Despite their limitations—such as vanishing gradients and slow training speeds—RNNs, along with advancements like LSTMs and GRUs, continue to drive significant improvements in machine learning applications.





