Introduction to MySQL
In the world of computing, we need to constantly store and retrieve our data to and from the database. The data can be stored in the form of databases, file structures or directories.
We use various database software to store and extract the results to and from our databases. These include MySQL, MS Access, Oracle, PostgreSQL, IBM DB2, MongoDB among others. Among these, MySQL is the most commonly used database system used to store and retrieve data.
History of MySQL
MySQL was founded in 1995 by MySQL AB, a Swedish business. Michael Widenius (Monty), David Axmark, and Allan Larsson were the platform’s creators. The primary goal was to give consumers efficient and dependable data management solutions, both at home and at work. By the year 2000, over a half-dozen alpha and beta versions of the platform had been launched. Almost all of the major platforms were supported by these versions.
1)Open-Source:
Originally owned by MySQL AB, the platform became open source in 2000 and began to follow the GPL conditions. Going open-source led to a considerable decrease in revenue, which was later regained. Due to MySQL’s open-source nature, it is available to contributions from third-party developers.
2)Expansion in Business:
MySQL grew in popularity among both household and professional users, with 2 million active installations by 2001. In addition to its Swedish headquarters, the corporation expanded its reach in 2002 by establishing a presence in the United States. In the same year, it was announced that the platforms’ membership had surpassed 3 million people, with revenue totalling $6.5 million.
3)First Lawsuit:
In June 2001, NuSphere sued MySQL AB in US District Court in Boston, which was the company’s first major legal battle. Third-party contract violations and unfair competition were among the charges. MySQL AB sued NuSphere for copyright and trademark infringement in 2002. After a preliminary hearing on February 27, 2002, both firms struck an agreement.
4)Shift in Strategy:
The platform grew in popularity, and by the end of 2003, it had generated $12 million in revenue and had 4 million active installations. In 2004, the company decided to place a greater emphasis on ongoing end-user revenue rather than one-time licence fees. The idea paid off, with net sales of $20 million at the end of the year.
What you can find in this article:
- Oracle’s Acquisition of Innobase
- Further Acquisitions of Oracle
- MySQL Acquired by Sun Microsystems
- Oracle’s acquisition of Sun and MySQL
- MySQL Forks
- MySQL and Cloud Computing
What is a Database?
Before mastering MySQL, it’s critical to understand the database. A database is a programme that organises and saves a collection of records. It is very simple for the user to access and manage. It allows us to rapidly access essential information by organising data into tables, rows, columns, and indexes. Each database has its API for conducting database tasks like generating, managing, accessing, and finding the information it holds. Many databases are available today, including MySQL, Sybase, Oracle, MongoDB, PostgreSQL, SQL Server, and others. In this section, we’ll mostly focus on MySQL.
RDBMS Terminology:
RDBMS stands for Relational Database Management System, and it is a database management system based on E.F Codd’s relational paradigm. Data is kept in relations (tables) and represented as tuples in the relational model (rows).
RDBMS is a relational database management system. A relational database is a collection of well-organized tables that are linked to one another and from which data may be easily accessed. These days, the most widely used database is the relational database.
What is Table?
A table is a collection of data components organised in rows and columns in a relational database format. A table can also be thought of as a convenient way to display relationships. A table, on the other hand, can have duplicate rows of data, whereas a genuine relation cannot. The most basic form of data storage is the table. An example of an Employee table is shown below.
| ID | Name | Age | Salary |
| 1 | Adam | 34 | 13000 |
| 2 | Alex | 28 | 15000 |
| 3 | Stuart | 20 | 18000 |
| 4 | Ross | 42 | 19020 |
What is a Tuple?
A Tuple, Record, or Row is a single entry in a table. A tuple in a table is a collection of related data. The Employee table, for example, has four tuples/records/rows.
An example of a single record or tuple is shown below.
| 1 | Adam | 34 | 13000 |
What is an Attribute?
A table is made up of numerous records (rows), each of which can be broken down into Attributes, which are smaller pieces of data. ID, Name, Age, and Salary are the four attributes in the Employee table above.
Attribute Domain
The Attribute Domain is defined when an attribute in a relation(table) is defined to hold just a specific type of value.
As a result, for each tuple, the attribute Name will store the employee’s name. It will be a breach of the Relational database concept if we save the employee’s address there.
| Name |
| Adam |
| Alex |
| Stuart – 9/401, OC Street, Amsterdam |
| Ross |
What is a Relation Schema?
A relation schema explains the relationship’s structure, including the connection’s name (table name), its characteristics, and its names and types.
What is a Relation Key?
A relation key is a property that can be used to identify a specific tuple (row) in a relation (table).
Relational Integrity Constraints
A relation key is a property that can be used to identify a specific tuple (row) in a relation (table).
To be a legitimate connection in a relational database model, each relation must adhere to or obey a set of constraints known as Relational Integrity Constraints.
The following are the three primary Integrity Constraints:
- Key Constraints
- Domain Constraints
- Referential integrity Constraints
Key Constraints:
We keep data in tables so that we can access it later as needed. To retrieve data from tables, one or more attributes are combined in each table. The Key Constraint states that any relation(table) should have an attribute(column) that may be utilised to obtain data for any tuple (row).
For two different rows of data, the Key attribute should never be NULL or the same.
For example, in the Employee database, the attribute ID can be used to retrieve data for each employee. ID has no null values and is unique for each row, so it may be used as our Key attribute.
Domain Constraint:
Domain constraints are the rules that govern the kind of values that can be stored for a certain attribute.
As previously stated, we cannot store an employee’s address in the Name column.
Similarly, a mobile phone number cannot be more than ten digits.
Referential Integrity Constraint:
We’ll take a closer look at this later. For the time being, remember that if I say Supraja is my girlfriend, then a girl named Supraja must also exist for that relationship to exist.
If a table refers to data from another table, that table and data must be present for the referential integrity constraint to hold.
What is MYSQL:
MySQL is the most widely used relational SQL database management system open source. MySQL is a popular relational database management system (RDBMS) for building web-based software applications.
This lesson will get you up to speed with MySQL and get you comfortable programming with it.
MySQL Database:
MySQL is a quick, easy-to-use relational database management system (RDBMS) that is utilised by many small and large enterprises. MySQL AB, a Swedish business, is responsible for its development, marketing, and support. MySQL is gaining popularity for a variety of reasons.
- MySQL is a free and open-source database. As a result, there is no cost to use it.
- MySQL is an extremely powerful programme in and of itself. It can handle a significant portion of the features found in the most expensive and sophisticated database solutions.
- MySQL makes use of a standard version of the widely used SQL data language.
- MySQL is compatible with a wide range of operating systems and languages, including PHP, PERL, C, C++, JAVA, and others.
- MySQL is a fast database that performs well even when dealing with massive amounts of data.
- MySQL is particularly friendly to PHP, the most popular web development language.
- MySQL can handle huge databases with up to 50 million rows in a table. The default file size limit for a table is 4GB, however, you can expand it to a theoretical limit of 8 million gigabytes (assuming your operating system can handle it) (TB).
- MySQL is adaptable. The MySQL software may be modified to fit a variety of contexts thanks to the open-source GPL licence.
How does My SQL works?

The diagram depicts the client-server architecture in its most basic form. Through a specialised network, one or more devices (clients) connect to a server. Every client can send a request using the graphical user interface (GUI) on their screens, and the server will respond with the intended result as long as both parties understand the request. Without going too technical, the following are the key processes that occur in a MySQL environment:
- MySQL generates a database to store and manipulate data, with each table’s relationship defined.
- Clients can submit requests to MySQL by inputting specified SQL statements.
- The requested information will be returned by the server application and displayed on the clients’ side.
That’s all there is to it. Clients frequently emphasise which MySQL GUI should be used. The faster and easier their data management operations are, the lighter and more user-friendly the GUI is. MySQL WorkBench, SequelPro, DBVisualizer, and the Navicat DB Admin Tool are some of the most popular MySQL GUIs. Some are free, while others are paid; some are exclusive for macOS, while others are compatible with all major operating systems. Clients should select the GUI that best suits their needs. The most obvious go-to for web database maintenance, including a WordPress site, is phpMyAdmin.
Key Features of MYSQL:
MySQL is a relational database management system (RDBMS) that uses SQL (Structured Query Language) queries to perform operations. It’s one of the most widely used languages for accessing and manipulating table records. Under the GNU licence, MySQL is open-source and free software. The Oracle Corporation is in favour of it.
The following are some of MySQL’s most essential features:
- Relational Database Management System (RDBMS):
MySQL is a database management system that uses a relational model. The SQL queries are used to retrieve and manage the table’s records in this database language.
2.Easy to Use:
MySQL is a simple database to work with. We merely need to learn the fundamentals of SQL. Only a few simple SQL statements are required to build and interact with MySQL.
3.Secure:
MySQL has a strong data security layer in place to keep sensitive data safe from hackers. In addition, MySQL encrypts passwords.
4. Client/ Server Architecture:
A client/server architecture is followed by MySQL. A database server (MySQL) and an unlimited number of clients (application applications) communicate with the server, allowing them to query data, make changes, and so on.
5. open-source:
MySQL is free to use, thus we can get it for free from the MySQL official website.
6. Scalable:
MySQL is scalable because it supports multi-threading. It can deal with virtually any quantity of data, up to 50 million rows or more. Approximately 4 GB is the default file size limit. However, we can theoretically boost this number to 8 TB of data.
7. Speed:
MySQL is regarded as one of the fastest database languages, as evidenced by numerous benchmark tests.
8. High Flexibility:
MySQL is particularly adaptable since it supports a huge range of embedded applications.
9. Compatible on many operating systems:
MySQL can run on a variety of operating systems, including Novell NetWare, Windows* Linux*, UNIX* (including Sun* Solaris*, AIX, and DEC* UNIX), OS/2, FreeBSD*, and others. MySQL also allows the clients to run on the same computer as the server or a separate machine (communication via a local network or the Internet).
10. Allows Rollback:
MySQL allows you to roll back, commit, and recover from a crash.
11Memory Efficiency:
Its efficiency is good because memory leakage is minimal.
12. High Performance:
Because of its unique storage engine architecture, MySQL is faster, more reliable, and less expensive. It achieves exceptionally good performance results when compared to other databases without sacrificing any of the software’s critical features. Because of the different cache memory, it features a quick loading utility.
13. High Productivity:
Triggers, stored procedures, and views are all used in MySQL to help developers be more productive.
14. Platform Independent:
It can be downloaded, installed, and run on the majority of operating systems.
15. Partitioning:
This feature boosts performance and allows for quick handling of huge databases.
16. GUI Support:
MySQL offers the “MySQL Workbench,” a unified visual database graphical user interface tool for database architects, developers, and database administrators. MySQL Workbench includes SQL development, data modelling, data migration, and server configuration, user administration, backup, and other administration utilities. From MySQL Server version 5.6 and higher, there is full GUI supports17.
17. Dual Password Support:
MySQL version 8.0 supports dual passwords: one is the current password, and the other is a backup password that we can use to switch to the new one.
MySQL Versions:
Versioning is the process of assigning distinct version names or numbers to a group of software programmes when they are created and distributed. The term “version 1.0” is widely used to refer to a software or program’s initial release. No industry standard guideline governs how version numbers are formatted. As a result, each corporation has its system for naming software versions. When new features in software and programmes are added, bugs are fixed, and security vulnerabilities are plugged in, the version number is changed to reflect these advancements.
The most recent version of MySQL support is version v5.8. Many important modifications have been made, including the addition and removal of new features, the correction of bugs and security issues, and so on. This version provides the MySQL 8.0 to MySQL 8.0.21 release history. It will be available starting in April 2018 and will be supported through April 2026.
When installing MySQL on your PC, you must select the version and distribution format you want to use. MySQL is available in two versions, the first of which is a development release and the second of which is a General Availability (GA) release. The development release contains the most recent feature and should not be used in production. The GA release, often known as the production or stable release, is primarily used for production. As a result, the most recent General Availability release must be chosen.
Let’s have a look at what’s new in MySQL 8.0.
Features Added in MySQL 8.0:
The following features have been added to MySQL 8.0:
Data Dictionary: The transactional data dictionary is used to hold information about database objects. Data was previously kept in metadata files and non-transactional tables in previous versions.
Atomic DDL Statement: It’s an atomic DDL statement that combines storage engine operations, data dictionary changes, and the binary log associated with a DDL operation into a single atomic transaction.
Upgrade Procedures: Previously, when a new MySQL version was installed, the data dictionary table was automatically upgraded at the next startup, and the DBA was expected to manually complete the upgrade process using the MySQL upgrade command. After MySQL 8.0.16, the DBA is no longer required to use the MySQL upgrade command to complete the upgrade.
Security and account management: Some enhancements have been made to strengthen security and give the DBA more flexibility in account management.
Resource Management: MySQL now allows you to construct and support resource groups, as well as assign threads to each group so that it can execute based on the resources available to it. The resource usage of threads in a group can be controlled by group characteristics.
Table Encrypt Management: Table encryption is now controlled at the system level by establishing and enforcing encryption defaults. When constructing a schema and general tablespace, the default table encryption variable or DEFAULT ENCRYPTION clause provides the encryption default.
InnoDB Enhancements: The auto-increment counter, index tree corruption, Memcached plugin, InnoDB deadlock detect, tablespace encryption feature, storage engine, InnoDB dedicated server, Zlib library, and many more InnoDB enhancements have been included.
Character Set Support: latin1 has been replaced by utf8mb4 as the default character set. Many new collations are included in the new character set, notably utf8MB JA 0900 as cs.
Data Type Support: It can support the usage of expressions as default values in data type specifications.
Optimizer Enhancements: This version includes improvements to the optimizer, such as invisible indexes, descending indexes, and the ability to create a functional index. It can compare a column to a constant value by using constant folding.
Window Function: Many new window functions, such as RANK(), LAG(), and NTILE, are supported in this version ().
JSON Enhancements: In MySQL’s json functionality, the following enhancements or additions are made: Inline path (->>) operator, json aggregate functions JSON ARRAYAGG() and JSON OBJECTAGG(), utility function JSON PRETTY(), JSON STORAGE SIZE(), JSON STORAGE FREE(), JSON STORAGE FREE(), JSON STORAGE FREE(), JSON STORAGE FREE(), JSON STORAGE FREE(), JSON STORAGE FREE() (). Instead of a set 1K size, each value is now represented by a variable-length part of the sort key when sorting json values. It also included the JSON MERGE PATCH merge function for combining two json objects, as well as the JSON TABLE() function.
Who Uses MYSQL:
Many database-driven web programmes, such as Drupal, Joomla, phpBB, and WordPress, use MySQL. Many major websites, such as Facebook, Flickr, MediaWiki, Twitter, and YouTube, use MySQL. All major companies use MySQL.
MySQL supported platforms:
The current version of MySQL Workbench is 8.0, and it is recommended for MySQL 8.0. It also supports MySQL 5.6 and 5.7.
Please keep in mind that MySQL Workbench for Linux is a Gnome application that is only officially supported on the Gnome desktop, however, it should work properly on other desktop environments as well.
| 8.0 | 5.7 | ||
| Operating System | Architecture | ||
| Oracle Linux / Red Hat / CentOS | |||
| Oracle Linux 8 / Red Hat Enterprise Linux 8 / CentOS 8 | x86_64, ARM 64 | • | |
| Oracle Linux 7 / Red Hat Enterprise Linux 7 / CentOS 7 | ARM 64 | • | |
| Oracle Linux 7 / Red Hat Enterprise Linux 7 / CentOS 7 | x86_64 | • | • |
| Oracle Linux 6 / Red Hat Enterprise Linux 6 / CentOS 6 | x86_32, x86_64 | • | • |
| Oracle Solaris | |||
| Solaris 11 (Update 4+) | SPARC_64 | • | • |
| Canonical | |||
| Ubuntu 21.04 | x86_64 | • | |
| Ubuntu 20.04 LTS | x86_64 | • | |
| Ubuntu 18.04 LTS | x86_32, x86_64 | • | • |
| SUSE | |||
| SUSE Enterprise Linux 15 / OpenSUSE 15 (15.2) | x86_64 | • | |
| SUSE Enterprise Linux 12 (12.5+) | x86_64 | • | • |
| Debian | |||
| Debian GNU/Linux 10 | x86_64 | • | • |
| Microsoft Windows Server | |||
| Microsoft Windows 2019 Server | x86_64 | • | |
| Microsoft Windows 2016 Server | x86_64 | • | • |
| Microsoft Windows 2012 Server R2 | x86_64 | • | • |
| Microsoft Windows | |||
| Microsoft Windows 10 | x86_64 | • | • |
| Apple | |||
| macOS 11 | x86_64, ARM_64 | • | |
| macOS 10.15 | x86_64 | • | |
| Various Linux | |||
| Generic Linux (tar format) | x86_32, x86_64, glibc 2.12, libstdc++ 4.4 | • | • |
| Yum Repo | • | • | |
| APT Repo | • | • | |
| SUSE Repo |
Minimum Hardware Requirements:
| Minimum | Recommended | |
| CPU | 64bit x86 CPU | Multi-Core 64bit x86 CPU, 8 GB RAM |
| RAM | 4 GB | 8 GB or higher |
| Display | 1024×768 | 1920×1200 or higher |
Minimum System Requirements for MySQL Enterprise Monitor Service Manager:
- a CPU with two or more cores
- Disk with 2 GB or more RAM I/O subsystem suitable for a database installation that requires a lot of writing.
System Requirements that are recommended: (If you’re watching over 100 MySQL servers):
- a CPU with four or more cores
- Disk with at least 8 GB of RAM RAID 10, RAID 0+1) I/O subsystem suitable for a write-intensive database installation
- * Use the built-in Agent to remotely monitor MySQL Instances operating on unsupported systems. Note that remote monitoring does not capture OS information; for further details, read the online documentation.
MySQL Supported third-party tools:
4.9 Third-Party Tools and MySQL Configuration
Third-party software can determine the MySQL version from the MySQL source by reading the VERSION file in the top-level source directory. The pieces of the version are listed separately in the file. For example, if the version is MySQL 5.7.4-m14, the file will look like this:
MYSQL VERSION MAJOR=5
MYSQL VERSION MINOR=7
MYSQL VERSION PATCH=4
MYSQL VERSION EXTRA=-m14.
The MYSQL VERSION EXTRA value is nonempty if the source is not for a MySQL Server General Availability (GA) release. The value corresponds to Milestone 14 in the prior example.
For NDB Cluster releases (including GA releases of NDB Cluster), MYSQL VERSION EXTRA is likewise nonempty, as illustrated here:
MYSQL VERSION MAJOR=5
MYSQL VERSION MINOR=7
MYSQL VERSION PATCH=32
MYSQL VERSION EXTRA=-ndb-7.5.21
Use the following formula to get a five-digit number from the version components:
MYSQL_VERSION_MAJOR*10000 + MYSQL_VERSION_MINOR*100 + MYSQL_VERSION_PATCH
Setting Up a MySQL User Account:
Please log in.
Go to your cloud servers and log in.
To connect to MySQL, type the following command:
MySQL -u root -p
You’ll be asked to enter your MySQL root password (note that this is not the same as the Cloud Server root password).
Make a new account for yourself:
You can create a new user and configure their password at the same time, as illustrated in the example command below, which creates a user with the username test:
CREATE USER ‘test’@’localhost’ WITH ‘newpassword’ AS IDENTIFIER;
After that, you must flush the privileges, which causes MySQL to reload the user table. This step must be completed each time you add or edit a user.
The command to flush privileges is shown in the following example:
FLUSH PRIVILEGES;
Done.
Permissions – Select
Make a new account for yourself:
Set the new user’s permissions.
Your new user (test) has no permissions and can’t do anything at this point. Starting with SELECT (read-only) permissions on all of the available databases, you might want to start setting permissions. By using the following command, you can grant specific permissions:
GRANT SELECT ON *. * TO ‘test’@’localhost’; Permissions – All
Add a new database and grant full access to test, allowing them to create, read, edit, and remove records, as demonstrated in the example below:
CREATE DATABASE mytestdb1; Now we have the database and the user, we can assign the privileges: GRANT ALL PRIVILEGES ON `mytestdb`. * TO ‘test’@’localhost’;
When creating a user and a database for a web application, this is the type of permission you’ll want to utilise. There is no requirement for the user to access any other databases.
Run the following command to clear the privileges:
FLUSH PRIVILEGES;
Log in with a new user account you’ve created…
Log in to MySQL as the new user and run the following command to verify that the permissions you set are correct:
MySQL -u test -p
Fill in the password for the test user when prompted.
After you’ve logged in as the test user, try issuing the following command to create a new database:
The following error message appears when you run CREATE DATABASE mytestdb2:
ERROR 1044 (42000): Access to database’mytestdb2′ is denied for user ‘test’@’localhost’.
Because the test uses only has ALL PRIVILEGES for the ‘mytestdb’ database and only SELECT privileges for everything else, this error occurs.
Remove/drop a user:
The procedure for deleting a user is similar to that of deleting a database. The example below demonstrates how to remove the test user:
DROP USER ‘test’@’localhost’;
Administrative MySQL Command:
Here is a collection of the most important MySQL commands that you may encounter while working with a MySQL database.
- USE databasename To pick a database in the MySQL work area, type the database name.
- SHOW DATABASES displays a list of databases that the MySQL DBMS may access.
- SHOW TABLES displays the database tables after using the use command to choose a database.
- SHOW COLUMNS FROM table name: Displays a table’s attributes, types of attributes, key information, if NULL values are allowed, defaults, and other data.
- SHOW INDEX FROM table name displays information about all of the table’s indexes, including the PRIMARY KEY.
- SHOW TABLE STATUS LIKE tablenameG displays information about the MySQL database management system’s performance and statistics.
MySQL Data Types:
The proper definition of a table’s fields is critical to the overall optimization of your database. You should only utilise the type and size of the field that you truly require. For example, if you know you’ll only use two characters, don’t make a field 10 characters large. After the sort of data, you’ll be storing in those fields, these fields (or columns) are referred to as data types.
MySQL makes use of a variety of data types that are divided into three groups.
- Numeric
- Date and Time
- String Types.
Numeric Data Type:
MySQL supports all of the standard ANSI SQL numeric data types, thus these definitions should be recognisable if you’re coming from another database system.
The common numeric data types and their descriptions are listed below.
INT: is a signed or unsigned integer of standard size. The allowed range, if signed, is -2147483648 to 2147483647. If the value is unsigned, the range is 0 to 4294967295. The width of up to 11 digits can be specified.
TINYINT : is a very small signed or unsigned integer. The allowed range, if signed, is -128 to 127. If the value is unsigned, the range is 0 to 255. The width of up to four digits can be specified.
SMALLINT: This is a small integer that can be either signed or unsigned. The allowed range, if signed, is -32768 to 32767. If the value is unsigned, the range is 0 to 65535. The width of up to 5 digits can be specified.
MEDIUMINT: This is a signed or unsigned medium-sized integer. The allowed range, if signed, is -8388608 to 8388607. If the value is unsigned, the range is 0 to 16777215. The width of up to 9 digits can be specified.
BIGINT: The size of a huge integer, which can be either signed or unsigned. The range allowed if signed is -9223372036854775808 to 9223372036854775807. If the value is unsigned, the range is 0 to 18446744073709551615. Width of up to 20 digits can be specified
FLOAT(M, D): This is a signed floating-point number that can’t be unsigned. The display length (M) and the number of decimals can both be customised (D). This is optional; the default value is 10,2, where 2 denotes the number of decimals and 10 denotes the total number of digits (including decimals). For a FLOAT, decimal precision can go up to 24 digits.
DOUBLE(M, D): A floating-point number with double precision that cannot be unsigned. The display length (M) and the number of decimals can both be customised (D). This is optional; the default value is 16,4, where 4 is the number of decimals. For a DOUBLE, decimal precision can go up to 53 digits. DOUBLE is a synonym for REAL.
DECIMAL(M, D): A signed floating-point number that has been unpacked. Each decimal in the unpacked decimals corresponds to one byte. It is necessary to specify the display length (M) and the number of decimals (D). DECIMAL is a synonym for NUMERIC.
DATE and Time Types:
The following are the MySQL date and time data types:
DATE: A date between 1000-01-01 and 9999-12-31 in the YYYY-MM-DD format. The date December 30th, 1973, for example, would be kept as 1973-12-30.
DATETIME: A date and time combination between 1000-01-01 00:00:00 and 9999-12-31 23:59:59 in the YYYY-MM-DD HH:MM: SS format. For example, on December 30th, 1973, 3:30 p.m. would be kept as 1973-12-30 15:30:00.
TIMESTAMP: A date between midnight on January 1, 1970, and the year 2037. This format appears to be similar to the previous DATETIME format, but without the hyphens between the digits; for example, 3:30 p.m. on December 30th, 1973 would be kept as 19731230153000. ( YYYYMMDDHHMMSS ).
TIME: TIME saves the time in the format HH:MM: SS.
YEAR(M): Stores a year as a two-digit or four-digit number. YEAR can be any year between 1970 and 2069 provided the length is specified as 2 (for example, YEAR(2)) (70 to 69). YEAR can range from 1901 to 2155 if the length is given as 4. The default length is 4 characters.
STRING TYPES:
Although the numeric and date formats are entertaining, the majority of your data will be stored in a string format. The following is a list of the most popular string datatypes in MySQL.
CHAR(M): A fixed-length string (for example, CHAR(5)) between 1 and 255 characters in length, right-padded with spaces to the specified length when stored. It is not necessary to specify a length, however, the default is 1.
VARCHAR(M): A variable-length string with a length of 1 to 255 characters. VARCHAR, for example (25). When creating a VARCHAR field, you must specify a length.
BLOB OR TEXT: A field that can hold up to 65535 characters. “Binary Enormous Objects,” or BLOBs, are used to store large volumes of binary data, such as photographs or other types of files. TEXT fields can also carry a lot of information. The distinction between the two is that on BLOBs, the sorts and comparisons on the stored data are case sensitive, whereas, in TEXT fields, they are not. With BLOB and TEXT, you don’t have to provide a length.
TINYBLOB or TINY TEXT: A maximum length of 255 characters for a BLOB or TEXT column. With TINYBLOB and TINYTEXT, you don’t have to provide a length.
MEDIUM BLOB or MEDIUM TEXT: The maximum length of a BLOB or TEXT column is 16777215 characters. With MEDIUMBLOB or MEDIUM TEXT, you don’t have to specify a length.
LONG BLOB or LONG TEXT: The maximum length of a BLOB or TEXT column is 4294967295 characters. With LONGBLOB and LONGTEXT, you don’t have to define a length
ENUM: A list is called an enumeration. You’re establishing a list of objects from which the value must be chosen when you define an ENUM (or it can be NULL). If you wanted your field to hold “A,” “B,” or “C,” you’d define your ENUM as ENUM (‘A,’ B,’ C,)
Earlier, the data was stored in DBMS structure but now the data is stored in RDBMS. The major difference between DBMS and RDBMS is the data format. In DBMS, the data is stored in file format whereas in RDBMS, the data is stored in tabular format. With the data being stored in tabular format, it becomes more structured and easy to read and understand.
All the above mentioned database systems including MySQL are a form of RDBMS database.
In MySQL, there are mainly 4 types of database commands to store and extract the data.
These include:
- DDL – Data Definition Language
- DML – Data Manipulation Language
- DCL – Data Control Language
- TCL – Transaction Control Language

DDL:
DDL or Data Definition Language consists of those commands which include defining the structure of database schema and database table. It mainly involves the structuring of database schema and the table.
The commands included in DDL are:
# Create – Used to create the table schema
# Drop – Drop the database from the memory
# Alter – Alter the structure of the table schema
# Truncate – Delete all the data from the database schema
# Comment – These statements are meant only for understanding the schema structure. They do not contribute to the actual database structure
# Rename – Used to rename the database table
DML:
DML or Data Manipulation Language consists of those commands which include manipulating the data of the database table. It involves creating and manipulating the data of the database table.
The commands included in DML are:
# Select: Used to extract the information from the database table
# Insert: Used to insert the data into the database table
# Update: Update the existing data in the database table where a particular condition is defined.
# Delete: Delete the data from the database table
DCL:
DCL or Data Control Language consists of those commands to deal with the rights, permissions, or other controls of the database system. It involves specific rights to the specific users to access the database.
The commands included in DCL are :
# Grant : Used to give permissions to a specific user to access the database with read or write permissions.
# Revoke : Used to remove the permissions from a specific user to access the database.
TCL:
TCL or Transaction Control Language consists of those commands that deal with the transactions of the database.These include collection of statements between specific client and server.
The commands included in TCL are:
# Commit : Used to store the previous data.
# Rollback : Used to restore the previous deleted data or tables.
# Savepoint : Used to create a point in the database also known as checkpoint. It is used to rollback the transaction.
KEYS:
Whenever we create the data in the database, there are chances of duplicate entries in the table. We can uniquely identify these values/records from the database by using specific columns or a combination of columns that are unique in nature also known as ‘keys’.
There are mainly 5 types of keys in the database:
- Primary Key: An attribute that can be used to identify every tuple uniquely in the resultant table is known as a primary key. There can be just a single primary key in the table.
- Candidate Key: A minimal set of attributes that can uniquely identify tuples in the record is called as a candidate key. There can be more than one candidate key in the table which are also known as composite keys.
- Super Key: A set of attributes which can uniquely identify a tuple in the record is called a super key. So a candidate key is a super key but vice-versa is not always true.
- Alternate Key: The candidate key which is not the primary key is known as an alternate key.
- Foreign Key: An attribute that can only take the values present as the values present as the values of some other attribute, is the foreign key to the attribute to which it refers.
CONSTRAINTS:
Whenever we define the structure of the database, we can create constraints on the column to make sure certain conditions are met before the value is accepted in that column.
Below mentioned are some of the constraints:
- NOT NULL: Used to ensure that a null value cannot be stored in a column
- UNIQUE: Used to make sure that all the values stored in a column are unique.
- CHECK: Used to make sure that all the values satisfy a particular condition before they can be accepted in a column
- DEFAULT: Used to define a set of default values when no value for a column is specified.
- INDEX: Used to store and retrieve data to and from the database very quickly.
Sorting Results:
There are multiple reasons why we need to sort the results as:
Data, which you want to sort, will not always be in the database(SQL in this case). If you take some data from the user as input but want to perform sorting before doing any operation then you have to have sorting in place in our code.
Sometimes your sorting logic might be very difficult(combination of multiple fields and operation). Our data may span across multiple tables. In real world problems, the type of data that we will be getting will not be straightforward. It will not be sorted in ascending or descending order. It will be very much unsorted. Sometimes we might have to perform some action before sorting. Our sorting logic might be needing multiple fields and multiple operations before sorting. Let’s take an example. We have 2 columns in table A (col1, col2) and 1 column in table B(col3). Because of some reason we need sorting order based on ( col1*Col2 + col3). ( Like a math problem for line equation mx+c). Now we can not perform using orders by SQL easily. That’s where we will need sorting in the code.
In some cases, sorting will be faster if done in code based on our data set. We may need different sorting algorithms for performance based on our data set. Everything depends on our data.
We need to study sorting algorithms to improve your algorithm designing and learn different approaches and patterns which you will be really needing in the IT world. We will never write bubble sort or heap sort in any company as it is. You just need to know the logic. All programming languages have sorting functions already implemented which you just need to call for sorting purposes. Those will be faster and well tested.
So we need to know all different approaches and possible solutions to solve a problem. One solution can not be best in all cases. Depending on the data and context, you will be needing different approaches. So we need to explore all the possible solutions and use them based on our needs.
- Select:
Whenever we fetch the results from a database using SQL Select query, we get the results in an unordered fashion.
Eg. Select * from employees;
This statement fetches all the results from the employee table but in a pre-ordered fashion. If we want the result to be displayed in an ordered manner, in that case we have to follow the next steps.
- Order by:
We can sort the results in SQL Select using ORDER BY clause and define the column name on the basis of which we want to sort the results.
Eg Select * from employees order by emp_id;
This statement fetches the results from the employee table and sorts the results on the basis of the emp_id column in ascending order.
By default, the results are obtained in ascending order.
- Desc:
We can also sort the results in descending order by using the “desc” keyword. Using desc keyword, all the results are displayed in descending order starting from the highest value displayed at the top and the lowest value displayed at the bottom.
Eg, Select * from employees order by emp_id desc;
- Sorting by multiple columns:
If there are two or more similar results obtained in a group, in that case we can use fancy indexing where the result is obtained by sorting the results on the basis of the first column and if the results clash, then we can sort the results on the basis of the second column.
Eg Select * from employees order by emp_id,salary;
When we try to sort the results based on 2 columns, in that case, the results are sorted initially on the basis of first column emp_id and then on the basis of second column salary.
- Limit:
We can also display the results by limiting the number of rows displayed by using the LIMIT function.
Eg select * from employees order by emp_id limit 3;
This statement displays the top 3 rows from the employees table sorting the results on the basis of the emp_id table in ascending order.
- Offset:
Whenever we use the LIMIT function, we display the top ‘n’ columns in our results. We can display the exact number of rows skipping a specific set of rows from the top using offset function.
Eg. Select * from employees order by emp_id limit 3 offset 2;
This statement would display the results of all employees from the employees table sorted by emp_id in ascending order displaying the top 3 rows after skipping the first 2 rows.
We sort the results from our database whenever we want to display the results from unstructured format to structured format.
Whenever we display the results in a website or a webpage by extracting the results from SQL Database, then we have to display the results in an ordered manner, eg. displaying the results of students.
There we use the sort function to display the results in an ordered manner.
Since not all data is stored in SQL Databases, some are stored in file systems and some are stored in directories too, so we need to learn different sorting algorithms to display the results in an ordered manner.
JOINS
Whenever we want to display the results from multiple tables with common values, we can join the tables in SQL.
SQL supports following types of joins in the tables:
1. Inner Join:
Inner join or implicit join is the most simple way to join the two tables. Whenever we want to join the two tables we simply select the common columns between the two tables on which the tables can be joined.
Inner join returns the records that have matching values in both the tables.
The following query shows inner join:
SELECT Orders.OrderID, Customers.CustomerName
FROM Orders
INNER JOIN Customers ON Orders.CustomerID = Customers.CustomerID;
2. Left Join:
Left join or Left outer join is a type of outer join that returns all records from the left table and the matched records from the right table.
The following query shows left join:
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
LEFT JOIN Orders ON Customers.CustomerID = Orders.CustomerID
ORDER BY Customers.CustomerName;
3. Right Join:
Right join or right outer join is a type of join that returns all records from the right table, and the matched records from the left table
The following query shows right join:
SELECT Orders.OrderID, Employees.LastName, Employees.FirstName
FROM Orders
RIGHT JOIN Employees ON Orders.EmployeeID = Employees.EmployeeID
ORDER BY Orders.OrderID;
4. Full Join:
Full join or full outer join is a type of join that returns all records when there is a match in either left or right table
The following query shows full join:
SELECT Customers.CustomerName, Orders.OrderID
FROM Customers
FULL OUTER JOIN Orders ON Customers.CustomerID=Orders.CustomerID
ORDER BY Customers.CustomerName;
5. Self Join:
Self join is a type of join where a table is joined with itself in SQL.
The following query shows self join:
SELECT A.CustomerName AS CustomerName1, B.CustomerName AS CustomerName2, A.City
FROM Customers A, Customers B
WHERE A.CustomerID <> B.CustomerID
AND A.City = B.City
ORDER BY A.City;
6. Cross Join:
Cross join is that type of join in SQL where every value from table 1 is joined with every other value in table 2.
The following query shows cross join:
SELECT foods.item_name,foods.item_unit,
company.company_name,company.company_city
FROM foods
CROSS JOIN company;
7. Equi-join:
In SQL, Equi-join performs a Join against equality or matching column(s) values of the associated tables. In equi-join , an equal to sign (=) is used as a comparison operator in the where clause to refer to equality of records.
We may also perform Equi-join by using JOIN keyword and then ON keyword and then specifying the names of the columns along with their associated tables to check equality.
The following query shows equi-join:
SELECT column_list FROM table1, table2....WHERE table1.column_name =
table2.column_name;
Equi-join vs Self-join:
Equijoin is a type of join with a join condition containing an equality(=) operator. An equi-join returns only those rows that have equivalent values for the specified set of columns.
Whereas, an inner join is a join of two or more tables that returns only those rows (compared using a comparison operator) that satisfy the join condition.
8. Natural Join:
In SQL, Natural Join is a type of Equijoin and is structured in a way that columns with the same name of associated tables will appear only once.
Natural join vs Inner Join:
The difference between Inner join and Natural Join is the number of columns returned.
NULL Values
In SQL, a column can contain NULL values. This means there exists no value for that particular record in the table. We can check the existence of NULL values in SQL using the following commands:
- IS NULL – This query returns true if the column value is NULL.
- IS NOT NULL – This query returns true if the column value is not NULL. Otherwise if the column value is NULL, false is returned.
- < = > – This operator compares values and returns true for 2 NON-NULL values.
The following query shows the NULL values in SQL:
SELECT * FROM table1 WHERE tutorial_count = NULL;
Here, the query returns all those records where the value of column tutorial_count = NULL
REGEXPS in SQL:
In SQL, we can use Regexps to match the string with a particular string or a subset of string. It is used to match the pattern to find a particular string with that pattern.
There are 3 ways to use regexp comparisons in SQL:
- Like
- Similar to
- Posix comparators
Like and similar to are used for basic comparisons where a particular string is used to match the matching string. If the pattern is matched, the corresponding string is returned as a result.
The following query shows the use of LIKE operator:
Select * from employees where emp_name LIKE ‘a%a’;
With Posix operator, we use the following operators to match the results:
- ~ : Match, case sensitive
- ~* : Match, not case sensitive
- !~ : No match, case sensitive
- !~* : No match, not case sensitive
We can also use the REGEXP operator to match the pattern. Below is the table that defines a list of operators to be used with REGEXP operators to match the desired string.
- ^ : Beginning of string
- $ : End of string
- . : Any single character
- […] : Any character listed between the 2 square brackets
- [^…] : Any character not listed between the 2 square brackets
- p1|p2|p3 : Alternation, match any of the patterns p1 or p2 or p3
- * : 0 or more instances of preceding element
- + : 1 or more instances of preceding element
- {x} : x instances of preceding element
- {x,y} : x through y instances of preceding element
We can use the following SQL query to show the use of REGEXP operator:
SELECT name FROM person_tbl WHERE name REGEXP '^st';
SELECT name FROM person_tbl WHERE name REGEXP 'ok$';
SELECT name FROM person_tbl WHERE name REGEXP 'mar';
SELECT FirstName FROM intque.person_tbl WHERE FirstName REGEXP '^[aeiou].*ok$';
ALTER COMMAND:
Alter command in SQL is used to change the database structure. We can add or remove columns. We can change the schema of the table column in SQL using the alter command. Alter command can also be used to rename the table. With the help of the alter command, we can also reposition the columns.
- Add column:
With the help of following query, we can add a column in SQL tables :
Alter table employee add name varchar(30);
This command adds a name column of varchar data type with length 30 characters into the table employee.
- Drop column:
With the help of following query, we can drop a column from SQL tables :
Alter table employee drop name;
This command drops the name column from the employee table
- Repositioning a column:
With the help of following queries, we can reposition a particular column in the SQL tables :
Alter table employee add salary int first;
This command adds the salary column of int type into the employee table at first position.
Alter table employee add salary int after name;
This command adds the salary column of int type into the employee table after the name column
- Setting a default value:
The following command helps set a default value to a particular column if an explicit value is not provided.
Alter table employee alter salary set default 1000;
This command sets the default value of salary column to 1000 if explicit value of salary column is not supplied.
- Changing a column definition:
Alter table employee modify name varchar(20);
This command alters the name column in employee table and modifies its data type to
varchar(20) by overriding its previous data type.
- Renaming a column:
- The following command alters the name of the table in SQL database.
- Alter table employee rename to emp;
- This command changes the name of the employee table and renames it to emp.
Alter command simply updates the structure of the database table. It can add, remove, reposition, rename the columns or simply rename the entire table of the database.
INDEXES IN SQL
SQL indexes are data structures used to improve the speed of operations in tables. Indexes can be created on one or more columns , thus providing the basis of both rapid and efficient table lookups.
Indexes are also a type of tables which keep a record of pointers which point to each record in the actual table.
Indexes can be of two types:
- Simple Index
- Unique Index
Simple indexing allows 2 rows to have the same index value whereas Unique does not allow 2 rows of a table to not have the same index value.
The following command helps create indexes in the database table.
Simple Index:
Create index my_index on employee( emp_name, salary);
Unique index:
Create unique index my_index on employee(emp_name, salary);
The above queries create an index my_index on the employee table with the columns emp_name and salary;
We can use the alter command to add or remove the indexes on an existing table.
- Alter table employee add primary key ( emp_name, salary )
This command adds a primary key index on the employee table
- Alter table employee add unique my_index (emp_name, salary)
This command adds a unique index my_index on the employee table in which 2 rows cannot have same index value ( unique indexing )
- Alter table employee add index my_ind (emp_name, salary)
This command adds an ordinary index my_ind on the employee table in which 2 rows can have same index value ( simple indexing )
- Alter table employee drop index my_index
This command drops the index my_index from the employee table.
Displaying indexes:
The following command can be used to display all the indexes in the SQL table.
Show index from employeeG
Here G is used to display the results in vertical order thus avoiding the long horizontal wrap-around results.
TRANSACTIONS IN DATABASE
In a database, a transaction is a sequential group of statements, which is performed as if it is one single unit.
A database must follow the following transaction properties :
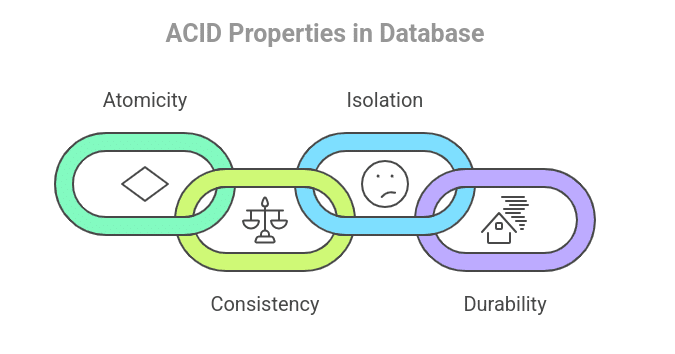
ACID
- (A)tomicity: It ensures that the transactions are either completed in full or are totally aborted. There should be no partial transaction that should take place in SQL. For eg. If fund transfer is to be done from account A to account B, then, either the complete transfer should take place or no transfer should take place. There should be no partial transaction taking place which debits money from account A and does not credit money into account B.
- (C)onsistency: The database should always remain in a consistent state. The database should be consistent after SQL query as it was consistent before the SQL query. Eg. When fund transfer takes place from account A to account B, then the sum of funds in account A and account B, should be always equal before and after the transaction.
- (I)solation: It ensures that if multiple transactions are running successfully in the database, then each transaction should not be affected by other transactions running in the database. For eg. if there are 2 write operations being performed in a single database, then there should be no interference between the two operations being performed. They should be executed in isolation.
- (D)urability: The database should be failure-proof. The changes made in the database system should be stored permanently even after a system of software failure. Eg. If account A has been credited with an amount of Rs. 50000, then that change should persist permanently in the account even after a system or software failure as it contains sensitive information related to the customer’s account.
COMMIT, ROLLBACK AND SAVEPOINT
Whenever we use transactions in a database, we create checkpoints also known as savepoints to mark the point in the database uptil where the transactions can be stored.
Commit: This command enables us to save the transactions in the database uptol a particular point in the database. All the queries or transactions upto a particular point are saved in the database.
Savepoint: A checkpoint is created which marks a point upto where the transactions could be saved or rolled-back in case of an error.
Roll-back: This command ensures us that a specific set of statements could be undone in case of an error upto a particular savepoint created. We need not reverse the entire transactions performed. Only a specific set of transactions are reversed back.
MySQL offers a feature of AUTOCOMMIT. We can set AUTOCOMMIT = 1, to make sure that the autocommit is ON. When autocommit is ON, then each and every transaction is automatically committed in the memory as soon as it gets executed.
TEMPORARY TABLE IN SQL
Temporary tables are used to store temporary data in SQL. These tables remain in memory until a particular session is alive or until they are manually destroyed.
Temporary tables are available only in the latest version of SQL. If we are using older versions of SQL, then temporary tables cannot be used. In that case heap tables can be used.
CREATE TEMPORARY TABLE SalesSummary (
product_name VARCHAR(50) NOT NULL
, total_sales DECIMAL(12,2) NOT NULL DEFAULT 0.00
, avg_unit_price DECIMAL(7,2) NOT NULL DEFAULT 0.00
, total_units_sold INT UNSIGNED NOT NULL DEFAULT 0
);
The above command creates the temporary table SalesSummary with the above defined column names and corresponding data types.
The values in temporary tables can be inserted using the simple insert command.
If we use the ‘Show Tables’ command, then the temporary tables will not be displayed.
Dropping temporary tables from the memory:
Though temporary tables are automatically deleted when the session terminates, still if we want to delete them, we can use the drop table command.
Drop table SalesSummary;
The above command deletes the temporary table SalesSummary from the database.
Closing Thoughts
This brings us to the end of the MySQL Tutorial. We hope that you are now better equipped with the concepts. If you wish to learn more such similar concepts, head over to Great Learning Academy and enroll in the Free Online Courses offered in various domains such as Artificial Intelligence, Machine Learning, MySQL, and much more.