- What are Recommendation systems?
- Use-cases of Recommendation systems
- Why Recommendation systems?
- What can be recommended?
- Real-World examples
- Various types of recommendation systems
- Popularity based recommendation system
- How to build a popularity based recommendation system in Python?
- Collaborative Filtering
- How to build a user-user collaborative filtering recommendation system in Python?
- Further Reading
- Our Machine Learning Courses
What are Recommendation systems?
Recommendation systems are becoming increasingly important in today’s extremely busy world. People are always short on time with the myriad tasks they need to accomplish in the limited 24 hours. Therefore, the recommendation systems are important as they help them make the right choices, without having to expend their cognitive resources.
The purpose of a recommendation system basically is to search for content that would be interesting to an individual. Moreover, it involves a number of factors to create personalised lists of useful and interesting content specific to each user/individual. Recommendation systems are Artificial Intelligence based algorithms that skim through all possible options and create a customized list of items that are interesting and relevant to an individual. These results are based on their profile, search/browsing history, what other people with similar traits/demographics are watching, and how likely are you to watch those movies. This is achieved through predictive modeling and heuristics with the data available.
Use-cases of Recommendation systems
Recommendations are not a new concept. Even when e-commerce was not that prominent, the sales staff in retail stores recommended items to the customers for the purpose of upselling and cross-selling, and ultimately maximise profit. The aim of recommendation systems is just the same.
Another objective of the recommendation system is to achieve customer loyalty by providing relevant content and maximising the time spent by a user on your website or channel. This also helps in increasing customer engagement.
On the other hand, ad budgets can be optimized by showcasing products and services only to those who have a propensity to respond to them. Check out the recommendation system python course and enhance your knowledge of other use cases.
Here is a video explaining the kind of recommendation systems used by BigBasket and Netflix:
Why Recommendation systems?
- They help the user find items of their interest
- Helps the item provider to deliver their items to the right user
- To identify the most relevant products for each user
- Showcase personalised content to each user
- Suggest top offers and discounts to the right user
- Websites can improve user-engagement
- It increases revenues for business through increased consumption
If you are new to Machine Learning, read "What is Machine Learning?"
What can be recommended?

- Advertising Messages
- Movies
- Books
- Music Tracks
- News Articles
- Restaurants
- Future Friends (Social Network Sites)
- Courses in e-learning
- Jobs
- Research Papers
- Investment Choices
- TV Programs
- Citations
- Clothes
- Online Mates (Dating Services)
- Supermarket Goods
Real-World examples
Here are some of the examples of the pioneers in creating algorithms for recommendation systems and using them to serve their customers better in a personalized manner. These are:
GroupLens:
- Helped in developing initial recommender systems by pioneering collaborative filtering model
- It also provided many data-sets to train models including MovieLens and BookLens
Amazon:
- Implemented commercial recommender systems
- They also implemented a lot of computational improvements
Netflix Prize:
- Pioneered Latent Factor/ Matrix Factorization models
Google-Youtube:
- Hybrid Recommendation Systems
- Deep Learning based systems
- Social Network Recommendations
Various types of recommendation systems
- Popularity based recommendation systems
- Classification model based
- Content based recommendations
- Nearest neighbour collaborative filtering
- User-based
- Item-based

- Hybrid Approaches
- Association rule mining
- Deep Learning based recommendation systems
Popularity based recommendation system
Let us take an example of a website that streams movies. The website is in its nascent stage and has listed all the movies for the users to search and watch. What the website misses here is a recommendation system. This results in users browsing through a long list of movies, with no suggestions about what to watch. This, in turn, reduces the propensity of a user to engage with the website and use its services. Therefore, the simplest way to fix this issue is to use a popularity based recommendation system. Top review websites like IMDb and Rotten Tomatoes maintain a database of movies and their popularity in terms of reviews and ratings. Utilising this data to recommend the most popular movies to users based on their star ratings, could increase their content consumption.
The popularity-based recommendation system eliminates the need for knowing other factors like user browsing history, user preferences, the star cast of the movie, genre, and other factors. Hence, the single-most factor considered is the star rating to generate a scalable recommendation system. This increases the chances of user engagement as compared to when there was no recommendation system.
Demerits of the popularity based recommendation system
- Recommendations are not personalized as per user attributes and all users see the same recommendations irrespective of their preferences
- Another problem is that the number of reviews (which reflects the number of people who have viewed the movie) will vary for each movie and hence the average star rating will have discrepancies.
- The system doesn’t take into account the regional and language preferences and might recommend movies in languages that a regional dialect speaking individual might not understand
A popularity based recommendation system when tweaked as per the needs, audience, and business requirement, it becomes a hybrid recommendation system. Additional logic is added to include customization as per the business needs.
How to build a popularity based recommendation system in Python?
For this exercise, we will consider the MovieLens small dataset, and focus on two files, i.e., the movies.csv and ratings.csv.
Movies.csv has three fields namely:
- MovieId - It has a unique id for every movie
- Title - It is the name of the movie
- Genre - The genre of the movie
The ratings.csv file has four fields namely:
- Userid - The unique id for every user who has rated one or multiple movies
- MovieId - The unique id for each movie
- Rating - The rating given to a user to a movie
- Timestamp - When was the rating given to a specific movie
#import all necessary libraries
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('seaborn-bright')
%matplotlib inline
#change directory to the folder where data files are present
#This step is not necessary if the data files and jupyter notebook are in same folder
os.chdir(r"C:UsersmirzaDownloadsCompressedml-latest-smallml-latest-small")
#import ratings file in a pandas dataframe
ratings_data=pd.read_csv("ratings.csv")
ratings_data.head()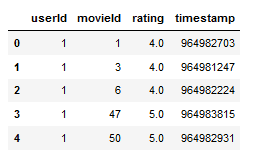
movie_names=pd.read_csv("movies.csv")
movie_names.head()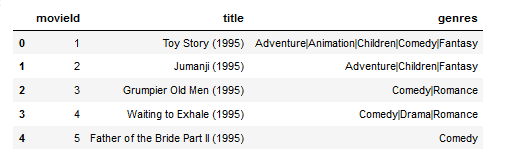
movie_data=pd.merge(ratings_data,movie_names,on='movieId')
movie_data.head()
#create a dataframe for analysis
trend=pd.DataFrame(movie_data.groupby('title')['rating'].mean())
trend['total number of ratings'] = pd.DataFrame(movie_data.groupby('title')['rating'].count())
trend.head()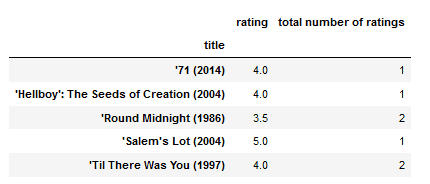
#plot rounded-up ratings with number of movies
plt.figure(figsize =(10, 4))
ax=plt.barh(trend['rating'].round(),trend['total number of ratings'],color='b')
plt.show()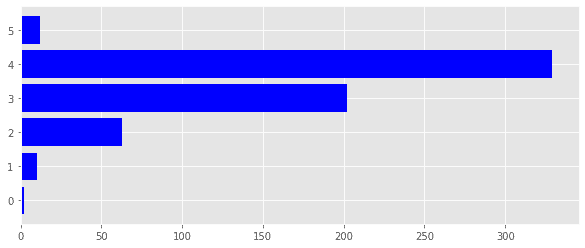
#a bar graph descibibg number of reviews for first 25 movies
plt.figure(figsize =(10, 4))
ax=plt.subplot()
ax.bar(trend.head(25).index,trend['total number of ratings'].head(25),color='b')
ax.set_xticklabels(trend.index,rotation=40,fontsize='12',horizontalalignment="right")
ax.set_title("Total Number of reviews for each movie")
plt.show()# Calculate mean rating of all movies and check the popular high rating movies
movie_data.groupby('title')['rating'].mean().sort_values(ascending=False).head()
The primary key here is the movieId which is common in both data files. This key makes it possible to join both these files.
Now, let us have a look at our Python code for popularity based recommendation system.
Step 1: Include the following packages to allow using functions defined under those packages. The cell will include:
- Import os
- Import numpy as np
- Import pandas as pd
Step 2: Change the working directory and replace it with where your dataset is stored
Step 3: Read the ratings file with the below command into the local variable ratings_data. ‘.head’ shows you the top five records in the data set. Also, you can see that we are using the pandas library in this cell which we had called earlier.
Similarly, read the movies file as below
Step 4: Merge the two data variables, ratings_data, and movie_names together by calling merge function from the pandas library on the column movieId. This gives a new data frame ‘movie_data’.
Print the movie_data head and you can have a look at the format this new variable appears in.
Step 5: Next, plot a horizontal bar graph using the 'barh' function of the matplotlib library to get an overview of data.We roundup the ratings of all the movies and plot a bar graph of the number of movies against the ratings they got.
Step 6: Next, we plot a bar graph describing the total number of reviews for each movie individually.
Step 7: Finally, we arrange the titles along with their ratings in defending order. This gives us a list of top-rated movies
Now, as mentioned earlier, a large number of users might be reviewing and rating certain movies. While as low as just one user might be rating the other movies. In such cases, some less popular movies can make it to the recommendation list and some of the more popular movies do not make it to the recommendation list. To avoid this bias, one can add a rule to better judge the popularity of a movie.
Moreover, newer movies could be more popular than the older ones even though the average ratings might suggest otherwise. In such cases, extra weight could be added to the rating values of the recently released movies to push them up in the recommendation list.
Collaborative Filtering
There are two types of collaborative filtering, namely:
- User - user collaborative filtering
- Item - item collaborative filtering
Let us understand this type of recommendation system with the help of an example. Say there are two users A and B.
Now, each of these users watched a number of movies and rated them as below:
| User A | User B | ||
| Movie | Rating | Movie | Rating |
| 1 | - | 3 | 5/5 |
| 2 | - | 4 | 1/5 |
| 3 | 5/5 | 6 | - |
| 4 | 1/5 | 7 | - |
| 5 | - | 8 | - |
Here, we can see that both A and B have two movies common and both have rated these movies in a similar manner. Hence, one can assume that both these users emanate similar characteristics and would like to see similar movies as each other.
Here, the recommendation system will recommend movies 1, 2, and 5 (if rated high) to user B because user A has watched them. Similarly, movies 6, 7, and 8 (if rated high) will be recommended to user A, (if rated high) because user B has watched them. This is an example of user-user collaborative filtering.
Measuring the similarity between users
One can measure the similarity between two users in different ways. A simple way would be to apply Pearson’s correlation to the common items. If the result is positively and highly correlated then the movies watched and liked by user A can be recommended to user B and vice-versa. On the other hand, if the correlation is negative then there is nothing to be recommended as the two users are not alike.
Limitations of user-user collaborative filtering
- A user might be watching a specific niche type of movies that nobody else is watching. Hence there are no similar profiles resulting in no recommendations.
- In case of a new movie, there are not enough user ratings to match
- In the case of a new user, there are not many movies that the user has watched or rated. Hence, it is difficult to map these users to similar users.
How to build a user-user collaborative filtering recommendation system in Python?
#import libraries specific to recommendation system
from surprise import KNNWithMeans
from surprise import Dataset
from surprise import accuracy
from surprise.model_selection import train_test_split
#load the movielens-100k dataset UserId :: MovieID :: Rating ::Timestamp
data=Dataset.load_builtin('ml-100k')Output:

#use user based true/false to switch between user-based or item-based collaborative filters
trainset,testset=train_test_split(data,test_size=.15)
algo=KNNWithMeans(k=50,sim_options={'name':'pearson_baseline','user_based':True})
algo.fit(trainset)Output:

#We can now query for speicific predictions
uid=str(196) #raw user id
lid=str(302) #raw item id
# get a prediction for specific users and items
pred=algo.predict(uid,lid,verbose=True) Output:
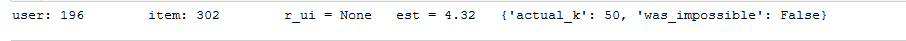
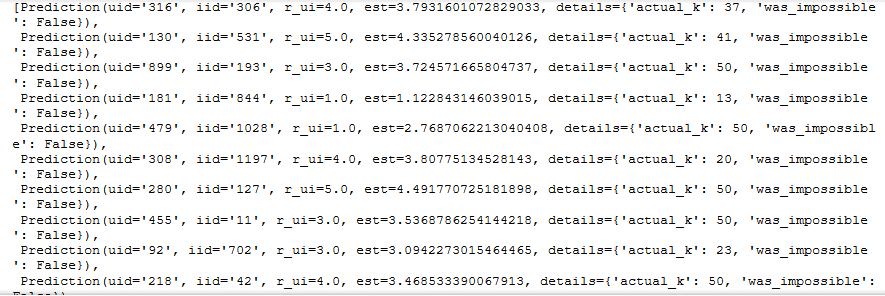
#run the trained model against the tesset
test_pred=algo.test(testset)
test_predOutput:
The library function used in order to get user-user collaborative filtering is ‘K nearest neighbours with means. It is a part of a library ‘surprise’, which stands for a simple python library for recommendation systems.
‘Surprise’ also consists of a sub-library called ‘dataset’ which includes some free datasets available to work on. It eliminates the need for downloading datasets from other sources. Another function that is included here is ‘train-test-split’. A portion of the data will be utilized for learning what needs to be recommended and another smaller portion to test the performance of the recommendation system.
Step 1: The first step is to install and import the surprise package. With pip (you’ll need numpy, and a C compiler. Windows users might prefer using conda):
#to install with pip
pip install numpy
pip install scikit-surprise
#to install with conda
conda install -c conda-forge scikit-surprise
Step 2: Load the inbuilt dataset ‘ml-100k’ and call it data. Split this data into two parts, i.e., 85% for training and 15% for testing.
Step 3: Apply KNNWithMeans as below. Then, fit the algorithm to the training set.
Here the function will display the 50 closest neighbours to a user which have rated the movies in a very similar way as the user being considered. The algorithm identifies these neighbours using ‘pearson_baseline’. This step accomplishes the training of the model.
Moreover, this model can also predict a rating that a user might give to a movie that he or she has not watched yet. Select a specific user id say 196, and a specific movie id say 302, which user 196 has not watched. Now, we can now predict the rating user will give to this movie with the help of the ‘algo’ defined above.
The model finds the nearest 50 neighbours and selects the ratings provided by these users for the movie 302. The average of these ratings is the predicted rating that the user 196 might give to the movie.
Also, the higher predicted rating means that the movie can be recommended to the user and he or she is much likely to click on it and watch.
Step 4: Test the model by passing test dataset (‘testset’) through the model (‘algo’) defined above. This will now predict the rating provided by each user for each movie in the data set.
In case the user or the movie is very new, we do not have many records to predict results. In such cases, the last value in the prediction will appear as ‘was_impossible’: True.
Step 5: Finally, measure the performance of the recommendation system by comparing predicted values and original rating values. Here we will calculate the ‘RMSE’ (root mean squared error) value.
In this case, the RMSE value is 0.9313, which one can judge if it is good or bad depending on the size of the dataset.
Here is the complete masterclass for you on movie recommendation system. Leave in your questions in comments and we would be glad to answer those for you.
These are two examples of recommendation systems and their implementation in Python.
If you wish to learn more about such concepts, you can enroll in AI and Machine Learning Courses and upskill today. Learn Artificial Intelligence from the best and gain access to career assistance as well. Upskill today and unlock your dream career. If you have any queries, feel free to leave them in the comments below.
Further Reading
Our Machine Learning Courses
Explore our Machine Learning and AI courses, designed for comprehensive learning and skill development.
| Program Name | Duration |
|---|---|
| MIT No code AI and Machine Learning Course | 12 Weeks |
| MIT Data Science and Machine Learning Course | 12 Weeks |
| Data Science and Machine Learning Course | 12 Weeks |