
INTRODUCTION -It is a sequence of items (objects) where every item is linked to the next. They are linked to one another through pointers. There are two parts in each node: the first part contains the data, and the second part contains the address of the next node in the linked list. Address part of the node which is connected to next is also called a link. The following Fig. 1. shows a typical example of a node.
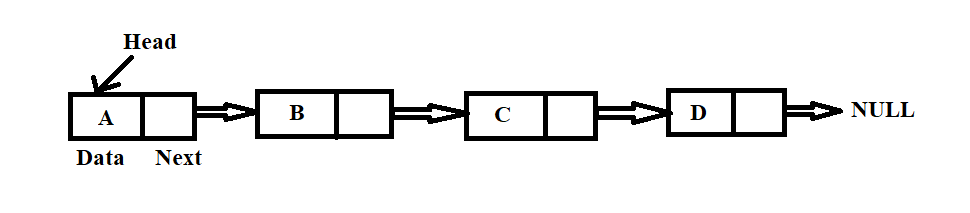
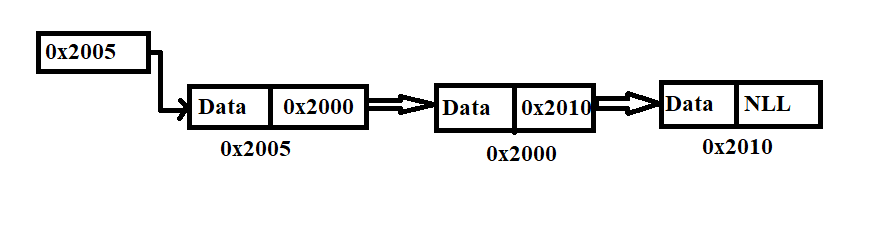
Fig. 2. shows a schematic diagram of a linked list. Each node is pictured with two parts. The left part of each node contains the data, and the right part represents the address of the next node. There is an arrow that shows that the first node is connected to the next node.
IMPLEMENTATION OF LINKED LIST
When we say linked list, we are talking about a singly linked list. There are various types of linked lists which we will discuss below, but here we are going to implement a singly linked list. There is a concept of pointer and structure, what structure data type is in C++ language, also, how to access the structure members using that structure variable and pointer.
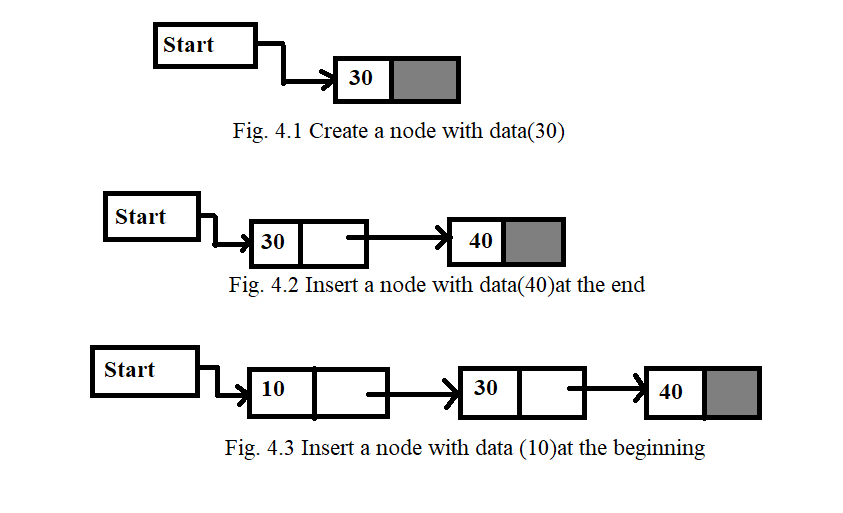
First of all, see the logical view of a linked list in Fig. 3, which shows the linked list having three nodes.

First, we have to create a node.
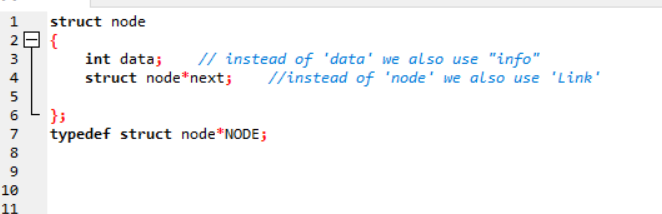
Creating a node using a user-defined data type, i.e. structure :
Also Read: Function overloading in C++
TYPES OF LINKED LIST
We can divide the linked list into the following three types mainly:
- Singly-linked list
- Doubly linked list
- Circular linked list
- Singly Linked List or One-Way Chain
In a singly linked list, all the nodes are arranged sequentially. A node in the singly linked list consists of two parts: the data part and the link/address part. The data part of the node stores actual information that is to be represented by the node, while the link or the address part of the node stores the address of its immediate successor.
A one-way chain or singly linked list can be traversed in one direction only; that is why it is known as a one-way chain. Fig. 4. shows the linked list.


- Doubly Linked List
In a singly linked list, as each node contains the next node’s address, it doesn't have any record of its previous node. However, a doubly-linked list will apply in place of a singly linked list. As we also know, each node of the list contains the address of its previous node of the linked list, so we can find all the details about the previous node by using the previous address stored inside the previous part of each node in a linked list.
Every node in the doubly linked list has three fields that are Left_Pointer, Right_Pointer and Data. Fig.5 shows a doubly linked list.

the point will point to the node on the left side (or previous node) that will hold the previous node’s address in a doubly-linked list. RPoint will point the right side (or next node) to the next node’s address in a linked list. Data will store the information of the node.

Representation of Doubly Linked List

- Circular Linked List
A circular linked list is one where there is no beginning and no end. A singly linked list can be made a circular linked list by simply storing the address of the first node in the linked field of the last node in a linked list. A circular linked list is shown in Fig. 6

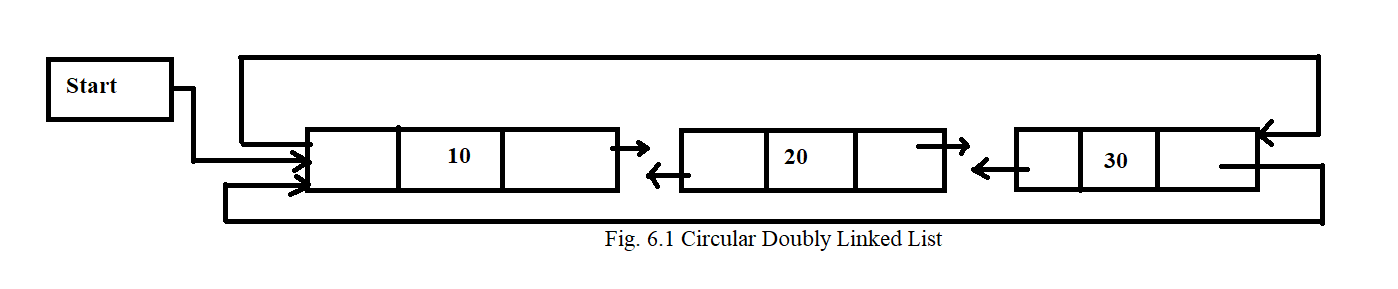
We can traverse a circular linked list until we reach the same node from where we started.
There is no null value present in any of the nodes in a circular linked list.
OPERATIONS ON LINKED LIST
The operations performed on the Linked List are as follows:
- Creation
- Insertion
- Deletion
- Traversing
- Searching
- Concatenation
Creation operation is used to create a node or linked list. When a linked list is created with one node, an insertion operation is used to add more elements to the node.
Insertion operation is used to insert a new node at any location in the linked list. A new node may be inserted:
- At the beginning of the linked list
- At the end of the linked list
- At any position in a linked list
Deletion operation is used to delete or remove a node from the linked list. A node may be deleted from the
- Beginning of a linked list
- End of a linked list
- Specified location of the linked list
Traversing is the process of going through each node from one end to another end of a linked list. In a singly linked list, we can visit from left to right, forward traversing, but we can not go from right to left. In a doubly-linked list, both side traversing is possible.
Concatenation is the process of appending the second list to the end of the first list in a linked list. Let us consider a list A having n nodes and B with m nodes. Then the concatenation will place the 1st node of B in the (n+1)th node in list A. After concatenation, A will contain (n+m) nodes in the list.
EXAMPLES:
OPERATIONS ON SINGLY LINKED LIST
Some operations can be performed on a singly linked list. A list of all the operations is given below.
Node Creation

INSERTION
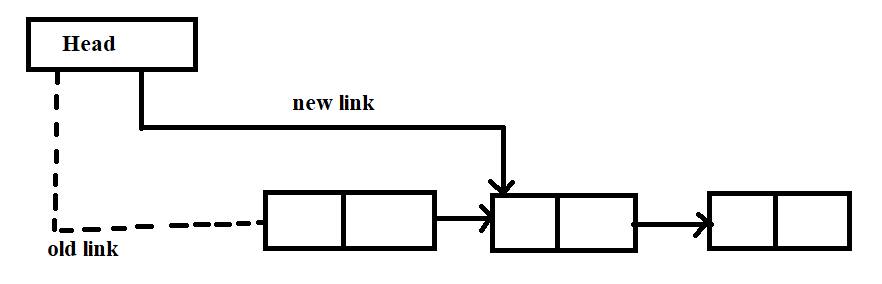
- Insertion in a singly linked list:
There are the following steps to insert a new node in the list.
• Allocate the space for the new node and store data into the data part of the node in the singly linked list.
• ptr = (struct node *) malloc(sizeof(struct node *)); o ptr → data = item
• Now, link part of the new node pointing to the first node of the list.
• ptr->next = head;
• Now, at last, we need to make the new node the first node of the list
• head = ptr;
Algorithm
STEP-1: IF PTR = NULL
Write OVERFLOW
Go to STEP-7
ELSE
STEP-2: SET NEW_NODE = PTR
STEP-3: SET PTR = PTR → NEXT
STEP-4: SET NEW_NODE → DATA = VAL
STEP-5: SET NEW_NODE → NEXT = HEAD
STEP-6: SET HEAD = NEW_NODE
STEP-7: EXIT

DELETION
Deletion in a singly linked list:
Deleting a node from the beginning of the list is the simplest operation of all the operations. Since the first node of the list is to be deleted, we have to make the head and point to the next of the head.
• ptr = head;
• head = ptr->next;
• The pointer ptr pointing to the head node is now free.
• free(ptr)
Algorithm
STEP-1: IF HEAD = NULL
Write UNDERFLOW
Go to STEP-5 [END OF IF]
STEP-2: SET PTR = HEAD
STEP-3: SET HEAD = HEAD -> NEXT
STEP-4: FREE PTR
STEP-5: EXIT

Traversing in a singly linked list
Traversing means visiting each node of the list when we perform operations on that.
ptr = head;
while (ptr!=NULL)
{
ptr = ptr -> next;
}
Algorithm
STEP-1: SET PTR = HEAD
STEP-2: IF PTR = NULL
WRITE "EMPTY LIST"
GOTO STEP-7
END OF IF
STEP-4: REPEAT STEP-5 AND 6 UNTIL PTR == NULL
STEP-5: PRINT PTR→ DATA
STEP-6: PTR = PTR → NEXT
[END OF LOOP]
STEP-7: EXIT
Searching in a singly linked list
Searching is used to find the location of a particular item in the list. The searching operation needs traversing through the list.
Algorithm
STEP-1: SET PTR = HEAD
STEP-2: Set I = 0
STEP-3: IF PTR = NULL
WRITE "EMPTY LIST"
GOTO STEP-8
END OF IF
STEP-4: REPEAT STEP-5 TO 7 UNTIL PTR == NULL
STEP-5: if ptr → data = item write i+1 End of IF
STEP-6: I = I + 1
STEP-7: PTR = PTR → NEXT
[END OF LOOP]
STEP-8: EXIT
OPERATIONS ON DOUBLY LINKED LIST:
Node Creation
INSERTION
Insertion in a doubly-linked list:
In the doubly linked list, each node of the list contains double pointers.
Algorithm
STEP-1: IF ptr = NULL Write OVERFLOW
Go to STEP-9 [END OF IF]
STEP-2: SET NEW_NODE = ptr
STEP-3: SET ptr = ptr -> NEXT
STEP-4: SET NEW_NODE -> DATA = VAL
STEP-5: SET NEW_NODE -> PREV = NULL STEP-6: SET NEW_NODE -> NEXT = START STEP-7: SET head -> PREV = NEW_NODE
STEP-8: SET head = NEW_NODE
STEP-9: EXIT

DELETION
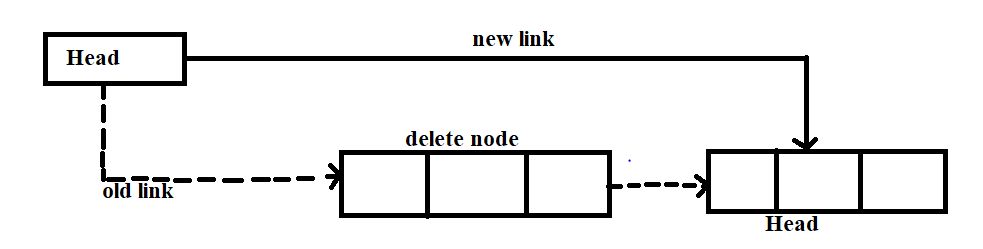
Deletion in a doubly-linked list
- For deletion in doubly linked lists, we have to copy the head pointer to pointer ptr. We also have to shift the head pointer to its next.
- Ptr = head;
- head = head → next;
- now make the prev of this new head node point to NULL(prev=NULL).
- head → prev = NULL
Algorithm
STEP-1: IF HEAD = NULL
WRITE UNDERFLOW
GOTO STEP-6
STEP-2: SET PTR = HEAD
STEP-3: SET HEAD = HEAD → NEXT
STEP-4: SET HEAD → PREV = NULL
STEP-5: FREE PTR
STEP-6: EXIT
Traversing in a doubly-linked list
- Copy the head pointer in any of the temporary pointers, here we will be using ptr.
- Ptr = head
- then traverse through the list. Keep shifting the value of the pointer variable ptr
until we find the last node of the list. The last node contains null.
- while(ptr != NULL)
- {
- printf("%dn",ptr->data);
- ptr=ptr->next;
- }
Algorithm
STEP-1: IF HEAD == NULL
WRITE "UNDERFLOW"
GOTO STEP-6
[END OF IF]
STEP-2: Set PTR = HEAD
STEP-3: Repeat STEP-4 and 5 while (PTR == NULL)
STEP-4: Write PTR → data
STEP-5: PTR = PTR → next
STEP-6: Exit
Searching in Doubly Linked List
- Copy head pointer into a temporary pointer variable, here we use ptr.
- ptr = head
- declare a local variable I for assigning its value as 0.
- i=0
- Traverse the list until the pointer becomes null(ptr==NULL). Keep shifting pointer to its next and increasing I by +1.
- Compare each element of the list with the other items which are to be searched.
Algorithm
STEP-1: IF HEAD == NULL
WRITE "UNDERFLOW"
GOTO STEP-8
[END OF IF]
STEP-2: Set PTR = HEAD
STEP-3: Set i = 0
STEP-4: Repeat STEP-5 to 7 while (PTR == NULL)
STEP-5: IF PTR → data = item return i
[END OF IF]
STEP-6: i = i + 1
STEP-7: PTR = PTR → next
STEP-8: Exit
OPERATION ON CIRCULAR SINGLY LINKED LIST:
INSERTION
Insertion into the circular singly linked list:
- In the first case, the condition head == NULL will be true. Since we know that, we are inserting the node is a circular singly linked list, so the node of the list will point to itself only.
- if(head == NULL)
- {
- head = ptr;
- ptr -> next = head;
- }
- The condition head == NULL will become false, this means that there is at least one node in the list. Here, we have to traverse the list for reaching that point.
- temp = head;
- while(temp->next != head)
- temp = temp->next;
- We have to make the next pointer of the last node point to the head node of the list.
- temp -> next = ptr;
- the next pointer of temp will point to the existing head node of the list.
- ptr->next = head;
- Make the new node ptr, which is a new head node of the circular singly linked list.
- head = ptr;
- In this way, we inserted the node ptr into the circular singly linked list.
Algorithm
STEP-1: IF PTR = NULL
Write OVERFLOW
Go to STEP-11
[END OF IF]
STEP-2: SET NEW_NODE = PTR
STEP-3: SET PTR = PTR -> NEXT
STEP-4: SET NEW_NODE -> DATA = VAL
STEP-5: SET TEMP = HEAD
STEP-6: Repeat STEP-8 while TEMP -> NEXT== HEAD
STEP-7: SET TEMP = TEMP -> NEXT
[END OF LOOP]
STEP-8: SET NEW_NODE -> NEXT = HEAD
STEP-9: SET TEMP → NEXT = NEW_NODE
STEP-10: SET HEAD = NEW_NODE
STEP-11: EXIT

DELETION
Deletion in a circular singly linked list:
To delete a node in a circular singly linked list, we have to make a few pointers for adjustments.
Case 1: (The list is Empty)
If the condition head == NULL will become true, which means the list is empty, in this case, we just need to print underflow.
if(head == NULL)
{
printf("nUNDERFLOW");
return;
}
Case 2: (The list contains a single node)
If the condition head → next == head will become true. This means the list contains a single node. In this case, we have to delete the entire list.
if(head->next == head)
{
head = NULL; free(head);
}
Case 3: (The list contains more than one node)
If there is more than one node in the list, then, in that case, we have to traverse the list by using the pointer ptr.
ptr = head;
while(ptr -> next != head) ptr = ptr -> next;
End of the loop, the pointer points to the last node. As the last node of the list points to the head node. Now, the last node point to the next of the head node.
o ptr->next = head->next;
• Now, by using the free() method in the C language, free the head pointer.
o free(head);
o head = ptr->next;
• By this way, the node deletion from the circular singly linked list will be successful.
Algorithm
STEP-1: IF HEAD = NULL
Write UNDERFLOW
Go to STEP-8
[END OF IF]
STEP-2: SET PTR = HEAD
STEP-3: Repeat STEP-4 while PTR → NEXT == HEAD
STEP-4: SET PTR = PTR → next
[END OF LOOP]
STEP-5: SET PTR → NEXT
HEAD → NEXT
STEP-6: FREE HEAD
STEP-7: SET HEAD = PTR → NEXT
STEP-8: EXIT
Traversing in Circular Singly linked list
Traversing in a circular singly linked list can be possible by using a loop. Initialize the temporary pointer variable, which is temp, and it points to the head pointer and runs the while loop.
Algorithm
STEP-1: SET PTR = HEAD
STEP-2: IF PTR = NULL
WRITE "EMPTY LIST"
GOTO STEP-8
END OF IF
STEP-3: REPEAT STEP-4 AND 5 UNTIL PTR → NEXT != HEAD
STEP-4: PRINT PTR → DATA
STEP-5: PTR = PTR → NEXT
[END OF LOOP]
STEP-6: PRINT PTR→ DATA
STEP-7: EXIT
Searching in a circular singly linked list
Searching in a circular singly linked list needs traversing. The item we want to search in the list is matched with each node data of the list once, if the match is found then the location of that item is returned otherwise -1 is returned.
Algorithm
STEP-1: SET PTR = HEAD
STEP-2: Set I = 0
STEP-3: IF PTR = NULL
WRITE "EMPTY LIST"
GOTO STEP-8
[END OF IF]
STEP-4: IF HEAD → DATA = ITEM WRITE i+1 RETURN
[END OF IF]
STEP-5: REPEAT STEP-5 TO 7 UNTIL PTR->next == head
STEP-6: if ptr → data = item write i+1 RETURN
End of IF
STEP-7: I = I + 1
STEP-8: PTR = PTR → NEXT
[END OF LOOP]
STEP-9: EXIT
OPERATION ON CIRCULAR DOUBLY LINKED LIST
INSERTION
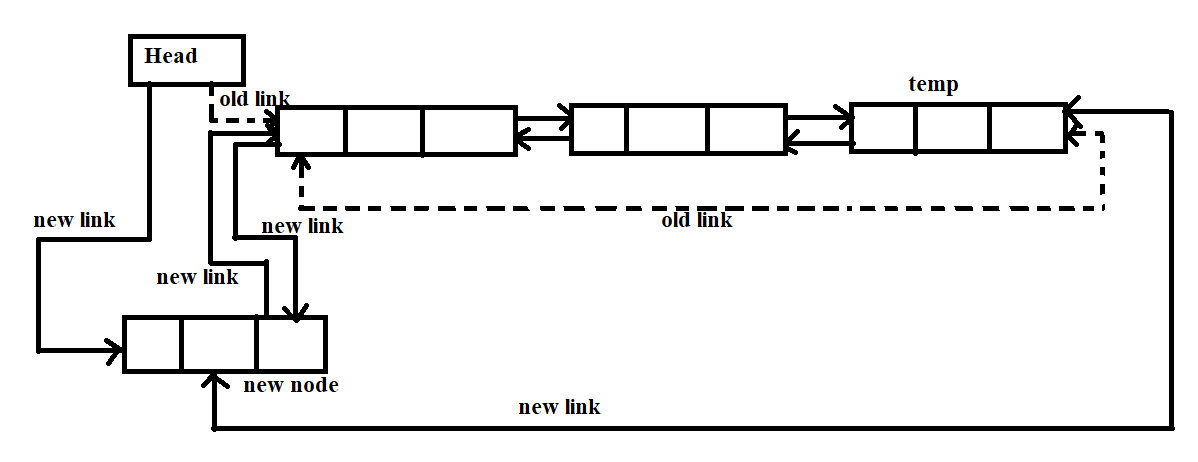
Insertion in circular doubly linked list:
ptr = (struct node *)malloc(sizeof(struct node));
- If the condition head == NULL becomes true then, the node will be added as the first node in the circular doubly linked list.
- head = ptr;
- ptr -> next = head;
- ptr -> prev = head;
- In the second scenario, the condition head == NULL becomes false. Then, we have to make a few pointers for adjustments. We have to reach the last node of the list by traversing through the list.
- temp = head;
while(temp -> next != head)
{
temp = temp -> next;
}
- Now at the end of the loop, the pointer temp would point to the last node of the list.
- temp -> next = ptr;
- ptr -> prev = temp;
- head -> prev = ptr;
- ptr -> next = head;
- head = ptr;
Algorithm
STEP-1: IF PTR = NULL
Write OVERFLOW
Go to STEP-13
[END OF IF]
STEP-2: SET NEW_NODE = PTR
STEP-3: SET PTR = PTR -> NEXT
STEP-4: SET NEW_NODE -> DATA = VAL
STEP-5: SET TEMP = HEAD
STEP-6: Repeat STEP-7 while TEMP -> NEXT == HEAD
STEP-7: SET TEMP = TEMP -> NEXT
[END OF LOOP]
STEP-8: SET TEMP -> NEXT = NEW_NODE
STEP-9: SET NEW_NODE -> PREV = TEMP
STEP-10 : SET NEW_NODE -> NEXT = HEAD
STEP-11: SET HEAD -> PREV = NEW_NODE
STEP-12: SET HEAD = NEW_NODE
STEP-13: EXIT
DELETION
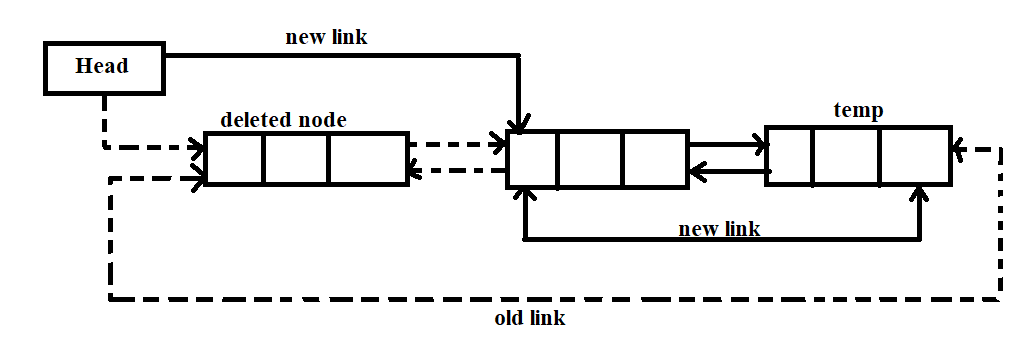
Deletion in a Circular doubly linked list:
- The conditioning head → next == head will become true, then the list needs to be completely deleted.
- Assign head pointer of the list to null(head==NULL).
- head = NULL;
- free(head);
- The list contains more than one element in the list, then the condition head → next == head will become false
- temp = head;
- while(temp -> next != head)
- {
- temp = temp -> next;
- }
- temp will point to the last node.
- temp -> next = head -> next;
- The new head node
- head -> next -> prev = temp;
- Now, free the head pointer and make its next pointer.
- free(head);
- head = temp -> next;
Algorithm
Step-1: IF HEAD = NULL
Write UNDERFLOW
Go to STEP-8
[END OF IF]
Step-2: SET TEMP = HEAD
Step-3: Repeat STEP-4 while TEMP --> NEXT == HEAD
Step-4: SET TEMP = TEMP -> NEXT
[END OF LOOP]
Step-5: SET TEMP -> NEXT
HEAD -> NEXT
Step-6: SET HEAD -> NEXT --> PREV = TEMP
Step-7: FREE HEAD
Step-8: SET HEAD = TEMP -> NEXT
Step-9: EXIT
ADVANTAGES AND DISADVANTAGES
ADVANTAGES
- Linked Lists are dynamic data structure.
- Efficient memory utilization. Memory is allocated whenever it is required.
- Insertion and deletion are easier and efficient as compilers to others.
DISADVANTAGES
- Memory is required to store an integer number is more.
- It is time-consuming.
REAL/ PRACTICAL APPLICATIONS OF LINKED LIST:-
There is much real-life example of linked lists like- Train cars/coach, traffic light, chains etc. If we decide it category wise then-
1) For a Singly linked list
- Child brain (eg. In case a child recited a poem, if you ask him the last line then, he will have to read from the first line of the poem again as he cannot remember the last line directly).
- Traffic light (there are three signals – red, yellow and green). If we are at a stop position in the traffic light, we will first see the red and the green signal. After green, we see the yellow signal for a few seconds, and we cannot go directly to the red signal.
2) Doubly linked list
- DNA double-helix structure
- Train coaches
- Roller chain of bicycle/bike
- Undo functionality in photoshop or word
3) Circular linked list
- The time-sharing problem used in the operating system.
- Boardgame (Multiple players)
- Used to repeat the songs in a playlist
- Audio-video streaming
Conclusion- These operations are functional in many real/ practical applications. We learned how to traverse, append, insert and delete nodes from the linked list. Suppose we take the example of a PowerPoint presentation, where nodes are slides that are serially linked with one another. Many other applications may require thinking of the function of the list, where the list can easily be maintained.
Learn C++ from basics to advanced concepts like OOP and memory management. With Our PRO C++ Programming for Beginners to Advanced course and it will help you build real-world skills for high-demand roles in software development, game programming, and more. Mastering C++ will give your career a boost with opportunities in industries like tech and finance.
Master key C++ programming concepts like variables, functions, OOP, and control structures. Build real-world projects such as a banking system and grade management tool.




