

Read about Dinesh’s journey with Great Learning’s PGP Artificial Intelligence and Machine Learning Course in his own words.
Executive Summary:
In any enterprise-wide digital transformation initiative, ‘data matching’ is critical: the ability to identify all records that point to the same entity within and across data sources. Here, the focus is on customer master data: the same customer is uniquely identified across different enterprise systems.
In other words, we deal with the de-duplication of customer master data. Data deduplication refers to the elimination of redundant data. In the deduplication process, duplicate data is deleted or linked together, leaving only one copy of the data to be stored.
The objective of this exercise is to ensure historical orders are tagged to the right customer sites in the Order Management system (EBS). It has been seen that many EBS orders are incorrectly tagged to the wrong site identifiers (UUID’s). A possible cause could be the inefficient account search mechanism while booking orders, resulting in duplication of identical customers.
SAP MDG houses the enterprise customer master data for VMWare. To rectify the duplication issue, VMWare Master Data (SAP MDG) customer data would be matched with EBS account data using account attributes such as Account name, address, city, and country. Accounts that have a 1-to-1 match between EBS and SAP MDG are considered correct. Those EBS accounts which didn’t match with MDG will go through various matching logic modules to identify the correct UUID from MDG.
Tools Used:
Python, SQL, R-Studio
1. Definitions and Algorithms:
EBS: Order management System
MDG: VMWare Master Data
1.1 Data cleaning:
Multiple methods are used to clean the EBS and MDG datasets. For any string-matching algorithms, it’s essential to have clean and consistent data to get relevant scores. This process was carried out in R-studio as we have a direct connection to the database.
1.1.1 Cleanco:
This is a Python package that processes company names, providing cleaned versions of the names by stripping away terms indicating organization type (such as “Ltd.” or “Corp”). Using a database of organization type terms also provides a utility to deduce the type of organization, in terms of US/UK business entity types (i.e. “limited liability company” or “non-profit”).
1.1.2 Removing Special Character’s
One of the data cleaning parts includes the removal of spaces, special characters, etc. with such elements in the string, they will create two entirely different strings even when they contain the same content.
e.g. String 1 = My name is Roger. String 2 = My $name @is Roger/
1.2 String Matching Algorithms:
There are many methods to calculate the similarity between strings. These steps are time-consuming and also require a huge amount of resources like RAM, processor and time for calculation. Around 10 million data points were served as input to these algorithms. Considering this, “String Matching” was implemented in Python. After Data cleaning, data was directly pulled in python.
The algorithms that are used in this exercise are discussed below.
1.2.1 Token Sort Ratio:
Fuzzy Wuzzy token sort ratio raw score is a measure of the string’s similarity as an int in the range [0, 100]. For two strings X and Y, the score is obtained by splitting the two strings into tokens and then sorting the tokens. The score is then the fuzzy-wuzzy ratio raw score of the transformed strings. Fuzzy Wuzzy token sort score is afloat in the range [0, 1] and is obtained by dividing the raw score by 100.
1.2.2 Cosine Similarity:
The cosine similarity between two vectors is a measure that calculates the cosine of the angle between them. This metric is a measurement of orientation and not magnitude, it’s a comparison between strings on a normalized space because we’re not taking into consideration only the magnitude of each word count of each string, but the angle between the string.
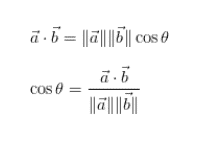
1.2.3 Jaro-Wrinkler:
Jaro-Winkler similarity places more weight on matching the first characters. If il is the largest number such that the first l characters S1 match those of S2, then the Jaro-Winkler similarity is defined as:
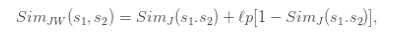
This method contains 3 steps:
1. Matches: The matching phase is a greedy alignment step of characters in one string against the characters in another string. The matching phase is a greedy alignment that proceeds character by character through the first string, though the distance metric is symmetric (that, is reversing the order of arguments does not affect the result). For each character encountered in the first string, it is matched to the first unaligned character in the second string that is an exact character match. If there is no such character within the match range window, the character is left unaligned.
2. Transpositions: After matching, the subsequence of characters matched in both strings is extracted. These subsequences will be the same length. The number of characters in one string that does not line up (by index in the matched subsequence) with identical characters in the other string is the number of “half transpositions”. The total number of transpositions is the number of half transpositions divided by two, rounding down. The Jaro distance is then defined in terms of the number of matching characters matches and the number of transpositions.
3. Winkler Modification: The Winkler modification to the Jaro comparison, resulting in the Jaro-Winkler comparison, boosts scores for strings that match character for character initially.
Output:
Once the output is ready, it was pushed in HIVE which users can access and use as per their requirement. This is stored in form of tables. These are Tableau dashboards in the pipeline which will use the above output tables and will be published on the VMWare operations site.
EBS: Order management System
MDG: VMWare Master Data
Implementation:
This logic is implemented when raw data is processed to create processed data for models. This has improved not only model accuracy but many dashboards which were using this data. Businesses can now see a clear view of all accounts while taking any business decisions.





