
Introduction
Before understanding Softmax regression, we need to understand the underlying softmax function that drives this regression. The softmax function, also known as softargmax or normalized exponential function, is, in simple terms, more like a normalization function, which involves adjusting values measured on different scales to a notionally common scale. There is more than one method to accomplish this, and let us review why the softmax method stands out. These methods could be used to estimate probability scores from a set of values as in the case of logistic regression or the output layer of a classification neural network, both for finding the class with the largest predicted probability.
Although simple mathematically, let us take some deliberate baby steps in understanding the softmax so that we could appreciate the subtle beauty of this technique. As a first step, let us understand the simplest form of normalization called ‘hard-max’. Let us assume our classification model has returned three values- 3, 7 and 14 as an output, and we want to assign probabilities or label them. The easiest possible way is to assign a 100% probability to the highest score and 0% to everything else, i.e. 14 would get a 100% probability score. In contrast, both 3, 7 would get probability scores of 0% each. Although simple, this method is relatively crude and does not consider the scores of other variables and their scales.
Next, let us consider the conventional normalization done by taking the ratio of the score to the sum of all scores. In the same model outputs- 3, 7 and 14 our probabilities would be 3/ (3+7+14) = 0.13, be 7/ (3+7+14) = 0.29 and be 14/ (3+7+14) = 0.58. Although this method takes into account the scores of other outputs other than the maximum value, it suffers from the following issues:
- It does not take into account the effect of scales, i.e. instead of outputs 3, 7 and 14, and if we had outputs of 0.3, 0.7 and 1.4, we would still end up with the same probability score outputs, namely 0.13, 0.29 and 0.58
- We would end up with negative probability scores of our outputs were negative values, which may not make mathematical sense.
Thus, it is imperative we resort to some other method that takes care of the aforementioned issues.
Enter, the softmax method, which is mathematically given by,
where, σ (z)i is the probability score, zi,j are the outputs and β is a parameter that we choose if we want to use a base other than e1 .
Features of Softmax:
Now for our earlier outputs 3, 7 and 14 our probabilities would be e3/ e (3+7+14) = 1.6 X 10-5, e7/ e (3+7+14) = 91 X 10-5 and e14/ e (3+7+14) =0.99 respectively. As you would have noticed, this method highlights the largest values and suppresses values that are significantly below the maximum value. Also, this is done proportional to the scale of the numbers, i.e. we would not get the same probability scores if the outputs were 0.3, 0.7 and 1.4, rather we would get the probability scores as 0.18, 0.27 and 0.55
In addition, even if we end up with negative values of outputs, the probability scores would not be negative (due to the property of the distribution)
Apart from these trivial properties, another interesting property of the softmax function makes it all the more attractive for neural network-based applications. This property is the ability of the softmax function to be continuously differentiable, making it possible to calculate the derivative of the loss function concerning every weight in the network for every input in the training set. Simply put, it makes things easier to update the weights in the neural network.
Relationship with Sigmoid/Logistic regression:
What if I said the sigmoid function (the one we use to model probabilities) in the logistic regression? You probably wouldn’t agree, as they might look very different at first stance. Now let us prove that the softmax function, which handles multiple classes, is a generalization of the logistic regression used for two-class classification.
We know that the softmax for k classes, with β=1 is given by:
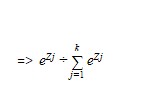
We also know that for a logistic regression, there are two-classes, x and non-x (or zero), plugging these in the formula above we get:
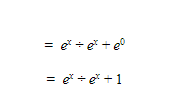
Now dividing the numerator and denominator by ex we get:
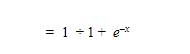
The above equation is nothing but the sigmoid function, thus we see how the softmax function is a generalization of the sigmoid function (for two-class problems).
Applications:
As mentioned earlier, softmax function/ regression finds utility in several areas, and some of the popular applications are as below:
Image recognition in convolutional neural networks: here, the last hidden layer would output values, which would be taken as an input by the output layer, then compute the probabilities using the softmax. The class with the highest probability would then be the final classification.
In reinforcement learning, the softmax function is also used when a model needs to decide between taking action currently known to have the highest probability of a reward, called exploitation, and taking an exploratory step, called exploration. Further details on how this is computed are out of the scope of this article but are available in the cited footnote.
Implementation:
Now that we’ve understood how the softmax function works, we can use that function to compute the probabilities predicted by a crude linear model, such as y= mx +b,
Initially, we can use the linear model to make some initial predictions. We can then use an optimization algorithm, such as gradient descent, that adjusts m and b to minimize the prediction errors in our model. Thereby we end up with a final softmax regression model with good enough m and b to make future predictions from the data. Although we use softmax for the probabilities, we will have to; assign a class to a data point based on the highest probability (such as argmax).
The same is represented in the schematic below. A detailed and nice write-up of the mathematics behind the model is also available here and has not been included in this article, as it is outside of the scope of this article.
The python implementation of the model on the iris dataset is as attached and embedded below. Here we take the iris dataset, which contains information on four flower characteristics: sepal length, sepal width, petal length, and petal width. Using this information, we try to predict one of 3 flower classes.
This brings us to the end of the blog on Softmax Regression, we hope that you were able to learn the concept well. If you wish to learn more such concepts, join Great Learning Academy's Pool of Free Online Courses and upskill today!





