


Hi there! My name is Prashanth. I am a freelance guitarist, a voracious reader, write code for fun, and a fitness enthusiast! I am a product design engineer with a background in Machine Design and over three years of experience in the industry. Read further to learn about my journey with Great Learning’s PGP Artificial Intelligence and Machine Learning Course.
My career trajectory thus far has involved structural and computational fluid dynamics analysis of wind turbines, Value analysis/Value Engineering (VAVE), Reverse engineering for new product development, and design of can decorators for the beverage industry. While my expertise primarily revolves around the machine design sphere, I have had some brushes with machine learning pilot projects in my organization.
Prior to enlisting in the correspondence course, I was involved in a pilot project related to the predictive maintenance of compressors for the petrochemical industry. The goal was to figure out ahead of time the prognosis (End of life estimation) of the compressor based on the propensity of failure of critical parts (valves, seals, piston rings, etc.). These components run in high-stress environments, and any catastrophic failure of them can incur huge downtimes in industries relying on these machines.
There was a lack of means to predict compressor critical part failure that led to unscheduled maintenance runs to assess component health. These overhauls can incur unintentional downtimes if it is found that the parts do not require replacement/repair.
There was no way to know when a compressor was close to failure during continuous duty operation. Failure of critical parts in the compressor, such as valves, seals, etc., subject to high temperature, pressure, and wear can have dire consequences on business and safety.
To cater to this likelihood, maintenance engineers would have to schedule maintenance runs at staggered intervals based on the life expectancies of these parts specified by the manufacturer. The problem here is that parts under assessment for defects will still be suited to run with desirable performance. This can inadvertently result in machine downtime that is being relied upon by several petrochemical companies, leading to production losses. The lack of a prognoses framework endangered workers on-site, notwithstanding the maintenance time and production losses impacting the customer.
The first order of business was to create a probabilistic model (weighted risk matrix) and determine the likelihood of component failure based on temperature, pressure, and vibration data supplied by the customer. Through brainstorming sessions, we determined the propensity of failure by assigning weights to the parameters of each of the compressor critical parts. The outcome was the most likely to fail part with the highest severity of impact.

By ranking the propensity of failure in this way, we were able to identify parts to focus on.
We conducted some studies on the wear of piston seals during the running condition, with data supplied by the customer (temperature, pressure, and seal material). With a theoretical understanding, we designed a transfer function highlighting a relationship between the diameter loss of seal and the number of compressor cycles. Using regression techniques, we input values of seal dimensions corresponding to failure based on past maintenance runs to predict the time taken for catastrophic failure.
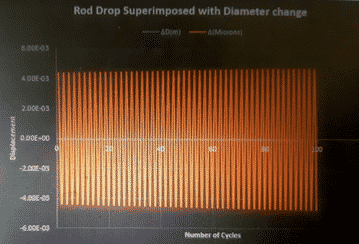
Average wear rate: 0.002 microns per cycle at a discharge pressure of 84 Bar and temperature of 80 C ambient temperature.
We recommended a sensor framework that will gather compressor data. By feeding this data into our regression model highlighted above, we can broadcast real-time predictions via the cloud that will notify production engineers on site. This will give them an idea of whether a machine is approaching failure and provide a solid decision ground to service the machine. There were 50000 USD saved annually due to increased uptimes of compressors.
Hands-on application of ML techniques has given me the confidence to experiment on other open-source datasets from Kaggle in the area of predictive maintenance. It also helped me in the Decision making process being streamlined.





