
- Understanding Retrieval Augmented Generation (RAG)
- RAG Workflow: How It Works
- Implementation with Vector Databases
- Practical Demonstration: Streamlit Q&A System
- Optimizing RAG: Chunking and Evaluation
- Deployment and LLM Ops Considerations
- Security in RAG Systems
- Future of RAG and AI Agents
- Actionable Recommendations
- Conclusion
Edited & Reviewed By-
Dr. Davood Wadi
(Faculty, University Canada West)
Artificial intelligence within the changing world depends on Large Language Models (LLMs) to generate human-sounding text while performing multiple tasks. These models frequently experience hallucinations that produce fake or nonsense information because they lack information context.
The problem of hallucinations in artificial models can be addressed through the promising solution of Retrieval Augmented Generation (RAG). RAG leverages external knowledge sources through its combination method to generate simultaneously accurate and contextually suitable responses.
This article explores key concepts from a recent masterclass on Retrieval Augmented Generation (RAG), providing insights into its implementation, evaluation, and deployment.
Understanding Retrieval Augmented Generation (RAG)
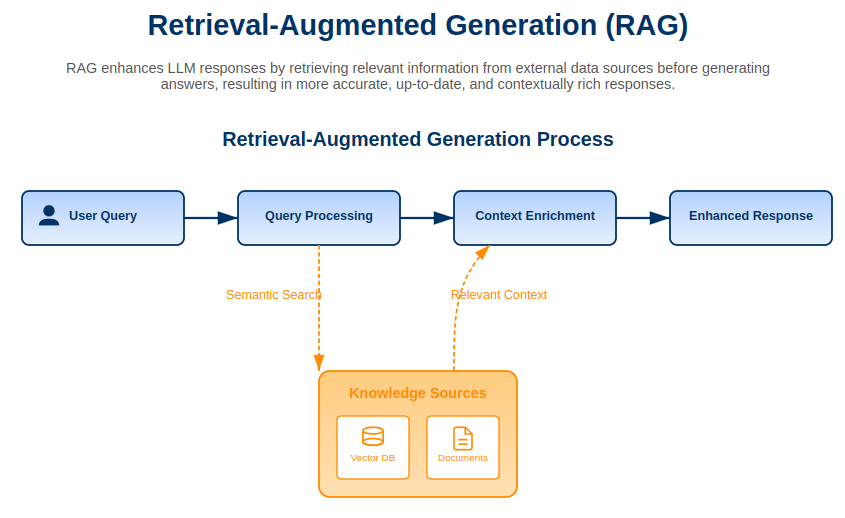
RAG is an innovative solution to enhance LLM functionality by accessing selected contextual information from a designated knowledge database. The RAG method fetches relevant documents in real time to replace pre-trained knowledge systems because it ensures responses derive from reliable knowledge sources.
Why RAG?
- Reduces hallucinations: RAG improves reliability by restricting responses to information retrieved from documents.
- More cost-effective than fine-tuning: RAG leverages external data dynamically instead of retraining large models.
- Enhances transparency: Users can trace responses to source documents, increasing trustworthiness.
RAG Workflow: How It Works
The RAG system operates in a structured workflow to ensure seamless interaction between user queries and relevant information:
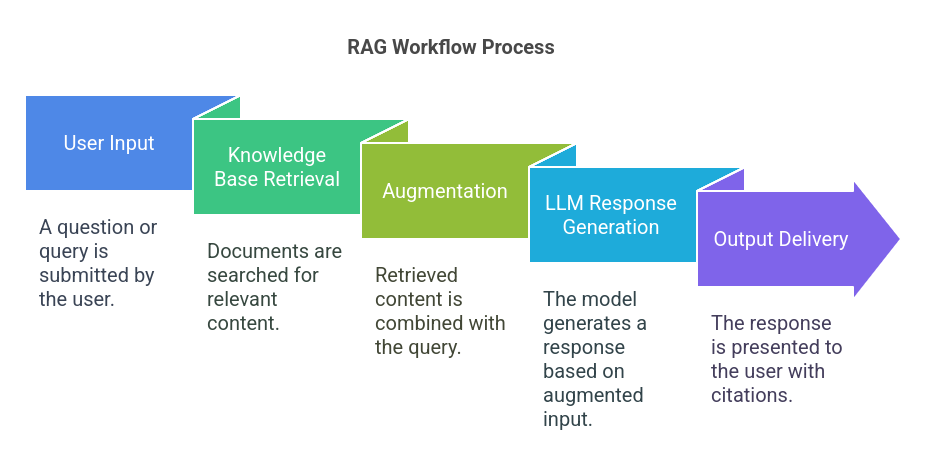
- User Input: A question or query is submitted.
- Knowledge Base Retrieval: Documents (e.g., PDFs, text files, web pages) are searched for relevant content.
- Augmentation: The retrieved content is combined with the query before being processed by the LLM.
- LLM Response Generation: The model generates a response based on the augmented input.
- Output Delivery: The response is presented to the user, ideally with citations to the retrieved documents.
Implementation with Vector Databases
The essential nature of efficient retrieval for RAG systems depends on vector databases to handle and retrieve document embeddings. The databases convert textual data into numerical vector forms, letting users search using similarity measures.
Key Steps in Vector-Based Retrieval
- Indexing: Documents are divided into chunks, converted into embeddings, and stored in a vector database.
- Query Processing: The user’s query is also converted into an embedding and matched against stored vectors to retrieve relevant documents.
- Document Retrieval: The closest matching documents are returned and combined with the query before feeding into the LLM.
Some well-known vector databases include Chroma DB, FAISS, and Pinecone. FAISS, developed by Meta, is especially useful for large-scale applications because it uses GPU acceleration for faster searches.
Practical Demonstration: Streamlit Q&A System
A hands-on demonstration showcased the power of RAG by implementing a question-answering system using Streamlit and Hugging Face Spaces. This setup provided a user-friendly interface where:
- Users could ask questions related to documentation.
- Relevant sections from the knowledge base were retrieved and cited.
- Responses were generated with improved contextual accuracy.
The application was built using Langchain, Sentence Transformers, and Chroma DB, with OpenAI’s API key safely stored as an environment variable. This proof-of-concept demonstrated how RAG can be effectively applied in real-world scenarios.
Optimizing RAG: Chunking and Evaluation
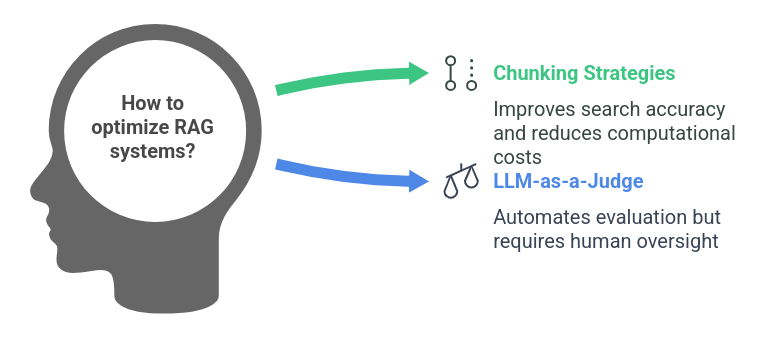
Chunking Strategies
Even though modern LLMs have larger context windows, chunking is still important for efficiency. Splitting documents into smaller sections helps improve search accuracy while keeping computational costs low.
Evaluating RAG Performance
Traditional evaluation metrics like ROUGE and BERT Score require labeled ground truth data, which can be time-consuming to create. An alternative approach, LLM-as-a-Judge, involves using a second LLM to assess the relevance and correctness of responses.
- Automated Evaluation: The secondary LLM scores responses on a scale (e.g., 1 to 5) based on their alignment with retrieved documents.
- Challenges: While this method speeds up evaluation, it requires human oversight to mitigate biases and inaccuracies.
Deployment and LLM Ops Considerations
Deploying RAG-powered systems involves more than just building the model—it requires a structured LLM Ops framework to ensure continuous improvement.
Key Aspects of LLM Ops
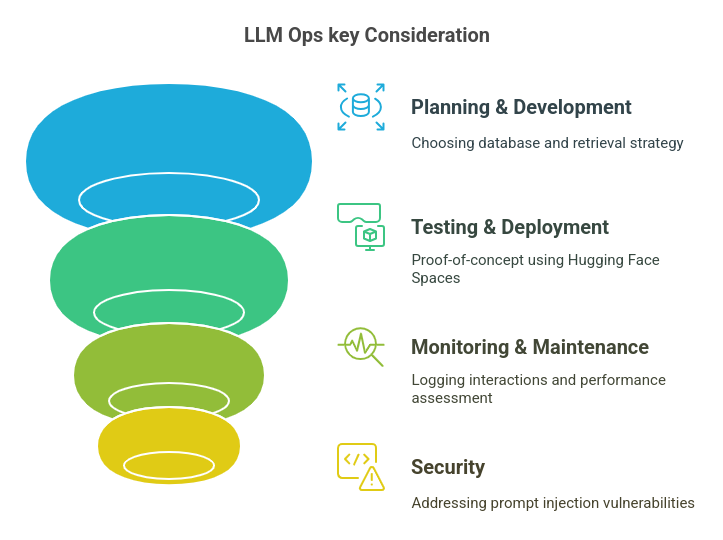
- Planning & Development: Choosing the right database and retrieval strategy.
- Testing & Deployment: Initial proof-of-concept using platforms like Hugging Face Spaces, with potential scaling to frameworks like React or Next.js.
- Monitoring & Maintenance: Logging user interactions and using LLM-as-a-Judge for ongoing performance assessment.
- Security: Addressing vulnerabilities like prompt injection attacks, which attempt to manipulate LLM behavior through malicious inputs.
Also Read: Top Open Source LLMs
Security in RAG Systems
RAG implementations must be designed with robust security measures to prevent exploitation.
Mitigation Strategies
- Prompt Injection Defenses: Use special tokens and carefully designed system prompts to prevent manipulation.
- Regular Audits: The model should undergo periodic audits to sustain its accuracy as a model component.
- Access Control: Access Control systems function to limit modifications for the knowledge base and system prompts.
Future of RAG and AI Agents
AI agents represent the next advancement in LLM evolution. These systems consist of multiple agents that work together on complex tasks, improving both reasoning abilities and automation. Additionally, models like NVIDIA Lamoth 3.1 (a fine-tuned version of the Lamoth model) and advanced embedding techniques are continuously improving LLM capabilities.
Also Read: How to Manage and Deploy LLMs?
Actionable Recommendations
For those looking to integrate RAG into their AI workflows:
- Explore vector databases based on scalability needs; FAISS is a strong choice for GPU-accelerated applications.
- Develop a strong evaluation pipeline, balancing automation (LLM-as-a-Judge) with human oversight.
- Prioritize LLM Ops, ensuring continuous monitoring and performance improvements.
- Implement security best practices to mitigate risks, such as prompt injections.
- Stay updated with AI advancements via resources like Papers with Code and Hugging Face.
- For speech-to-text tasks, leverage OpenAI’s Whisper model, particularly the turbo version, for high accuracy.
Conclusion
The retrieval augmented generation method represents a transformative technology that enhances LLM performance through relevant external data-based response grounding. The combination of efficient retrieval systems with evaluation protocols and deployment security techniques allows organizations to build trustable artificial intelligence solutions that prevent hallucinations and enhance both accuracy and protection measures.
As AI technology advances, embracing RAG and AI agents will be key to staying ahead in the ever-evolving field of language modeling.
For those interested in mastering these advancements and learning how to manage cutting-edge LLMs, consider enrolling in Great Learning’s AI and ML course, equipping you for a successful career in this field.








