


Objective of Crime Data Analysis
As we are marching towards becoming a “developed country”, crimes are also increasing alarmingly. Hence as a part of this project, we have developed a solution using the technology that we learnt (AWS and Big data services) in order to provide more sophisticated environment to the Crime Department to store crime-related data, analyse and get the meaningful insights which would help them to make appropriate decisions to bring down the crime rate.
Use Cases of Crime Data Analysis
Considering the volume, variety and frequency of data, it is very difficult to manually analyse and make meaningful patterns out of it. Hence our solution to address these issues are as follow:
- Provide a more sophisticated environment to store different kinds of crime data
- Provide information about different kinds of crimes as per the different region and magnitude. This information would help them to focus on giving more importance to the critical areas.
- Provide information about different kinds of crime occurring over different time frames, locations, crime against women, traffic-related crime etc.,
- Provide an environment to store historical data
- Pictorial representation of different location with different colour codes to make the comparative assessment
- Provide a solution to trace criminals by using their picture
Implementation
The implementation has been divided into multiple streams. They are,
- Data Migration Stream (DMS): The assumption here is that most of the crime department is using a legacy database to store their on-going crime data which is a handicap for them to accommodate different kinds of data. Hence as part of this project, we would like to propose a more sophisticated AWS environment to store their crime data in order to accommodate the volume and variety of the data. The data migration involves movement from the legacy in-house SQL Oracle RDS to NoSQL Amazon DynamoDB.
- Descriptive Analytics: Launching the Amazon Hadoop EMR Cluster to accommodate the huge volume of crime data and enable the web connections to use Hive to get intelligent and meaningful insights.
- Ad-hoc and Interactive Analytics: As part of this stream we are proposing Amazon Athena to get quick answers for a single, specific business question. Also as an extension to this, they can use Amazon Quicksight to run complex queries across different data landscapes to get the detailed dashboard which would be useful for them to do a comparative analysis to make meaningful decisions.
- Real-time analytics: This is to help the crime department to get meaningful information immediately from the stream of data being injected into their system, which would help them to make quicker decisions and react without any delay. In this case, we have assumed to use FIR (First Investigation Report) data being injected from different locations across geographies. Lambda function has been used to read and process the stream of in-coming FIR data on to Amazon Kinesis data stream and used Amazon Kinesis RT Analytics to trap meaningful insights. Finally, we have used Amazon Kinesis Firehose to get them stored on Amazon Redshift for historical purposes.
- Amazon REKOGNITION: Used Amazon Rekognition service to compare pictures and identify the person who committed the crime.
Architecture
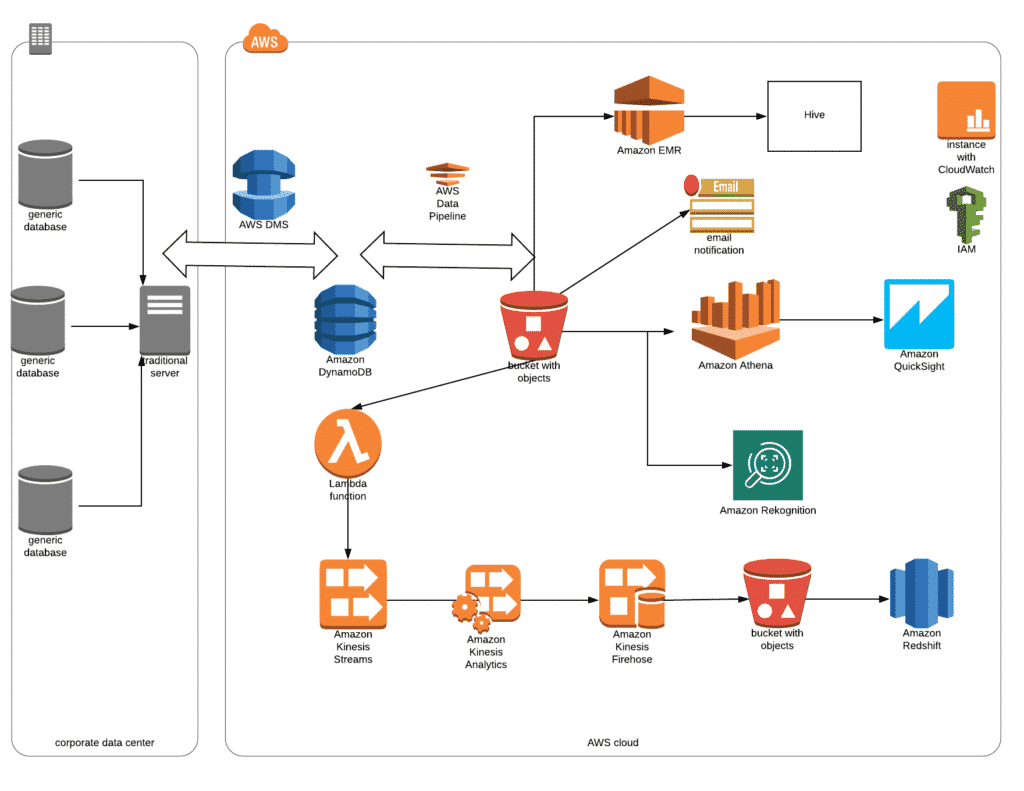
1. AWS Data Migration Services (DMS) Implementation
Create VPC, SUBNET and Security Group
Virginia region has been chosen to do this project. Crime data VPC with CIDR block 10.0.0.0/16 has been created with two public subnets (crimedata-subnet1 at the address 10.0.1.0/24 in AZ1 and crimedata-subnet2 at the address 10.0.2.0/24 in AZ2). New Security group has been created with enabling port 1521 to access Oracle RDS.
Create Oracle RDS DB; Setup Schema and Tables
Created Oracle RDS database of Standard Edition One with these deployment options:
- License Included
- Single-AZ setup
- db.t3.micro or equivalent instance class
- Port 1521
- Default option and parameter groups
Logged-in onto Oracle RDS. Created the necessary Schema and Tables to store the Crime data.
Create DMS Replication Instance, Source and Target End Points
Created the replication instance, source and target end points and executed the migration task. Upon successful migration, verified the tables are created with the crime data in DynamoDB.
2. Descriptive Analytics Implementation
Create S3 Buckets
Instead of reading the crime data directly from DynamoDB, an intermediate S3 bucket has been created to store and re-direct crime data to multiple channels simultaneously and also to store the Data Pipeline logs as well.
Create an SNS Topic
Necessary SNS Topic is created and mapped on to the Data Pipeline process to denote the success and failure of data migration activity. This topic has been subscribed to by the concerned e-mail ID which will be notified upon completion of the Data Pipeline process. This would help the Crime department to get to know the readiness of crime data, and hence they can launch the EMR cluster to get the data insights.
Create Hadoop EMR Cluster, Crime Table and Load Crime data
EMR cluster has been created with 1 master and 1 core instance. Necessary Security Groups are assigned to enable the Web-connections. New Crime table has been created using the External Table and the Crime data from S3 has been loaded onto the EMR Cluster table.
Launch Hive and Get The Data Insights
Upon successful completion of data load onto the EMR Cluster table, Hue is launched to get meaningful data insights. Crime department can use this service to construct complex SQL queries to fetch data from the crime table. Using Hadoop EMR cluster services enable us to store the large volume of data and process them quickly.
3. Ad-hoc and Interactive Analytics Implementation
Create an External Table, Crime Table and Load Crime data
Amazon Athena service is chosen to send ad-hoc and interactive queries to the crime data stored in the Crime Table which has been created using the External Table. Athena service uses standard SQL based queries and the data can be both structured and unstructured. In this implementation, we have used CSV format files stored in S3 buckets.
Run Interactive Ad-hoc SQL Query in Athena
SQL Query has been framed and executed in Athena to get the data from the crime table. Like this, users can load data and get insights by using SQL queries on their own.
Dashboard with AWS BI (Quicksight) Using Datasets from Athena
Crime data analysis is done using Quicksight dashboard. We created a dashboard using dataset sourced from Athena Crime table. We used SPICE to import data into Quicksight from Athena to improve performance for faster analytics and queries. Dataset imported is refreshed daily using SPICE schedule. Dashboard gives a quick visual reference for the reports of crime based on the type, state, heatmap etc
4. Real-time Analytics Implementation
Streaming the FIR Data
Kinesis API has been used to pump the FIR data continuously as a producer. Kinesis data stream is created with 1 shard as a consumer to continuously process the incoming FIR data. We’ve built this producer using the AWS SDK for Java and Kinesis Producer Library. Necessary IAM access (S3FullAccess and KinesisFullAccess) are given to the EC2 access in order to access both S3 and Kinesis stream respectively.
Kinesis RT Analytics
Kinesis data stream has been set as an input stream to this RT Analytics application. This application will read and analyse the FIR data stream as it is being injected continuously in real-time. SQL option has been chosen as a Runtime parameter to frame SQL query to get the FIR data insights. COLS in this application is tailored to meet the number of columns from the input data stream in order to get them displayed as appropriate in the screen. This includes mapping their data types as well. Once these are done, then the SQL Query has been written to pull the respective record from the stream of FIR record that have been pumped as an input, which would help the Crime department to take speedy actions.
Kinesis Data Firehose and Redshift
We created a new delivery stream to load the FIR data, automatically and continuously to Redshift through an intermediate S3 bucket. Redshift cluster (DB & Table) has been created up-front and that has been mapped as a destination to Kinesis Firehose. Similarly, S3 bucket has been created up-front and that has been mapped as an intermediate destination prior to copying the data onto the Redshift cluster. Amazon Redshift Copy command has been used to copy the data from S3 to Redshift.
5. Amazon REKOGNITION
Photo images are used from the S3 bucket. These images are fed into Rekognition service to match and get the confidence level of the match, which would help the Crime department to take appropriate action.
Business and Technical Challenges:
Business Challenges and Solutions
- Collating the data to meet the demand of all the streams was fulfilled by referring crime data from the official crime department website, but the official data was huge and it covered varied interests. Using the data as it is would be definitely hit the cost budget of this project. Hence we finalised the analytics part and then worked backwards from there and trimmed the official data to feed into different streams to showcase the outcomes.
- Getting real-time data (FIR data) to process real-time analytics was the other challenge. To overcome this we have used Kinesis API to pump the streaming of real-time data and pushed onto the Kinesis data stream.
- Initially, we thought of having multiple Oracle SQL tables on-premises and use SCT (Schema Conversion Tool) to convert and load them onto NoSQL DynamoDB table, but considering the cost factor and to simplify the process in the project perspective, we have directly created the data in Oracle as how it is expected in DynamoDB, then migrated as a one-on-one process using DMS services.
Technical Challenges and Solutions
- We thought of using Hue4 but settled with Hue3 as it enables better performance.
- Using External Tables to create a table in the EMR cluster and load the crime data directly from S3 failed due to insufficient access, but this has been managed by tweaking the process.
- As it is cumbersome to get real-time data from the Crime department, we have used AWS metadata for the real-time simulation. Also, issues faced to map the columns from the input data with the COLS in Kinesis RT analytics and in the order that needs to be followed and that the type needs to be synced up etc., all these were successfully resolved to produce real-time analytics.
Learning
- How to use APIs and AWS metadata
- How to convert and map SQL data onto NoSQL set up
- Using the right region consistently for all the streams. This is very important because sometimes AWS assumes Oregon as a default region, but when we tried to merge different components, we found that some of the components developed using other regions were not getting synced with components developed using the default region. We can avoid re-work by religiously following this.
- Make sure that all the components are cleaned up properly across regions. Some of the components were left behind when we created them in different regions, but those wouldn’t show in the Console unless you switch back to the respective region. You may end up spending more money if you don’t identify and delete components across regions.
About the Author
Kannan Poompatham is a senior IT project manager with more than 20+ years of experience in the IT industry. Though primarily focusing on delivering IT projects to different customers across the globe, he has a keen interest in building solutions using IoT, Cloud, and Big Data Analytics.
If you want to pursue a career in Cloud Computing, then upskill with Great Learning’s PG program in Cloud Computing (PGP-CC).





