- Big data– Introduction
- What is Big data?
- Types of data:
- Let us look at the 6 V's of Big Data
- Challenges in Big data
- Big Data Technologies
- Hadoop Tutorial Introduction
- Distributed Computing
- Why Hadoop?
- History of Hadoop
- Hadoop Framework: Stepping into Hadoop Tutorial
- Master Slave Architecture(80)
- HADOOP Deployment Modes
- Hadoop Ecosystem
- Master nodes
- What is a job in the Hadoop ecosystem?
- Core features of Apache Hadoop
- Submitting and executing a job in a hadoop cluster
- Splitting of file into blocks in HDFS
- File storage in HDFS
- Failure of a data node
- Replication of Data blocks
- Replica Placement Strategy
- Name node and secondary name node in Hadoop 1.0
- Hadoop Installation
- HDFS- Basic commands
- Mapreduce: A Programming Paradigm
- THE MAP STAGE
- The sort operation
- REDUCE STAGE:
- Programming the reducer
- Summary
- Closer look to Map reduce
- Final Output of the Reducer?
- How does Map reduce speed up the processing?
- Why Map Reduce?
- Use Case of MapReduce?
Big data– Introduction
Before we jump into our Hadoop Tutorial, lets understand Big Data. Will start with questions like What is Big data, Why big data, What big data signifies so that the companies/industries are moving to big data from legacy systems, is it worth it to learn big data technologies and will professional get paid high? Learn Apache today!
What is Big data?
By name implies, big data is data with huge size. We get a large amount of data in different forms from different sources and in huge volume, velocity, variety and etc which can be derived from human or machine sources.
We are talking about data and let us see what are the types of data to understand the logic behind big data.
Types of data:
Three types of data can be classified as:
Structured data: Data which is represented in a tabular form. The data can be stored, accessed and processed in the form of fixed format. Ex: databases, tables.
Semi structured data: Data which does not have a formal data model. Ex: XML files.
Unstructured data: Data which does not have a pre-defined data model. Ex: Text files, web logs.
Learn more about Structured, Unstructured, and Semi-Structured Data
Let us look at the 6 V's of Big Data
Volume: The amount of data from various sources like in TB, PB, ZB etc. It is a rise of bytes we are nowhere in GBs now.
Velocity: High frequency data like in stocks. The speed at which big data is generated.
Veracity: Refers to the biases, noises and abnormality in data.
Variety: Refers to the different forms of data. Data can come in various forms and shapes, like visuals data like pictures, and videos, log data etc. This can be the biggest problem to handle for most businesses.
Variability: to what extent, and how fast, is the structure of your data changing? And how often does the meaning or shape of your data change?
Value: This describes what value you can get from which data, how big data will get better results from stored data.
Challenges in Big data
Complex: No proper understanding of the underlying data
Storage: How to accommodate large amounts of data in a single physical machine.
Performance: How to process large amounts of data efficiently and effectively so as to increase the performance.
Big Data Technologies
Big Data is broad and surrounded by many trends and new technology developments, the top emerging technologies given below are helping users cope with and handle Big Data in a cost-effective manner.
- Apache Hadoop
- Apache Spark
- Apache Hive
There are many other technologies. But we will learn about the above 3 technologies in detail.
Also Read: Introduction to JavaScript
Hadoop Tutorial Introduction
Hadoop is a distributed parallel processing framework, which facilitates distributed computing.
Now to dig more on Hadoop Tutorial, we need to have understanding on “Distributed Computing”. This will actually give us a root cause of the Hadoop and understand this Hadoop Tutorial. To learn more, you can also take up Free Hadoop Courses learn gain comprehensive knowledge about this in-demand skill.
Distributed Computing
In simple English, distributed computing is also called parallel processing. Let's take an example, let's say we have a task of painting a room in our house, and we will hire a painter to paint and may approximately take 2 hours to paint one surface. Let's say we have 4 walls and 1 ceiling to be painted and this may take one day(~10 hours) for one man to finish, if he does this non stop.
The same thing to be done by 4 or 5 more people can take half a day to finish the same task. This is the simple real time problem to understand the logic behind distributed computing
Now let's take an actual data related problem and analyse the same.
We have an input file of lets say 1 GB and we need to calculate the sum of these numbers together and the operation may take 50secs to produce a sum of numbers
Then let's take the same example by dividing the dataset into 2 parts and give the input to 2 different machines, then the operation may take 25 secs to produce the same sum results.
This is the fundamental idea of parallel processing.
Why Hadoop?
The idea of parallel processing was not something new!
The idea ws existing since long back in the time of Super computers (back in 1970s)
There we used to have army of network engineers and cables required in manufacturing supercomputers and there are still few research organizations which use these kind of infrastructures which is called as “super Computers”.
Lets see what were the challenges of SuperComputing
- A general purpose operating system like framework for parallel computing needs did not exist
- Companies procuring supercomputers were locked to specific vendors for hardware support
- High initial cost of the hardware
- Develop custom software for individual use cases
- High cost of software maintenance and upgrades which had to be taken care in house the organizations using a supercomputer
- Not simple to scale horizontally
There should be a better reason always! HADOOP comes to the rescue.
- A general purpose operating system like framework for parallel computing needs
- Its free software (open source) with free upgrades
- Has options for upgrading the software and its free
- Opens up the power of distributed computing to a wider set of audience
- Mid sized organizations need not be locked to specific vendors for hardware support – Hadoop works on commodity hardware
- The software challenges of the organization having to write proprietary softwares is no longer the case.
Data is everywhere. People upload videos, take pictures, use several apps on their phones, search the web and more. Machines too, are generating and keeping more and more data. Existing tools are incapable of processing such large data sets. Hadoop and large-scale distributed data processing, in general, is rapidly becoming an important skill set for many programmers. Hadoop is an open-source framework for writing and running distributed applications that process large amounts of data. This " Hadoop map reduce course" introduces Hadoop in terms of distributed systems as well as data processing systems. With this course, get an overview of the MapReduce programming model using a simple word counting mechanism along with existing tools that highlight the challenges of processing data at a large scale. Dig deeper and implement this example using Hadoop to gain a deeper appreciation of its simplicity.
History of Hadoop
Before getting into the Hadoop Tutorial, let us take a look at the history of Hadoop.
- The need of the hour was scalable search engine for the growing internet
- Internet Archive search director Doug Cutting and University of Washington graduate student Mike Cafarella set out to build a search engine and the project named NUTCH in the year 2001-2002
- Google's distributed file system paper came out in 2003 & first file map-reduce paper came out in 2004
- In 2006 Dough Cutting joined YAHOO and created an open source framework called HADOOP (name of his son's toy elephant) HADOOP traces back its root to NUTCH, Google's distributed file system and map-reduce processing engine.
- It went to become a full fledged Apache project and a stable version of Hadoop was used in Yahoo in the year 2008
Hadoop Framework: Stepping into Hadoop Tutorial
Let us look at some Key terms used while discussing Hadoop Tutorial.
- Commodity hardware: PCs which can be used to make a cluster
- Cluster/grid: Interconnection of systems in a network
- Node: A single instance of a computer
- Distributed System: A system composed of multiple autonomous computers that communicate through a computer network
- ASF: Apache Software Foundation
- HA: High Availability
- Hot stand-by: Uninterrupted failover whereas cold stand-by will be there will be noticeable delay. If the system goes down, you will have to reboot
Master Slave Architecture(80)
Lets try to understand the architectural components of Hadoop 1.0 in this Hadoop Tutorial-
For example:
Suppose there are 10 machines in your cluster, out of which 3 machines will always be working as ’ Masters’ and it will be names as-
Namenode
Secondary name node
Job tracker
These 3 will be individual machines and will work in the master mode.
The rest of the 7 machines in “Slave” mode and they will wait for instructions from the master and these nodes are called as Data nodes.
All these will be interconnected to each other and all these machines are belonging to a cluster.
HADOOP Deployment Modes
HADOOP supports 3 configuration modes when its is implemented on commodity hardware:
Standalone mode : All services run locally on single machine on a single JVM (seldom used)
Pseudo distributed mode : All services run on the same machine but on a different JVM (development and testing purpose)
Fully distributed mode: Each service runs on a separate hardware (a dedicated server). Used in production setup.
Note: Service here refers to namenode, secondary name node, job tracker and data node.
Hadoop Ecosystem
As we learn more in this Hadoop Tutorial, let us now understand the roles and responsibilities of each component in the Hadoop ecosystem.
Now we know Hadoop has a distributed computing framework, now at the same time it should also have a distributed file storage system. Hadoop has a built- in distributed file system called HDFS which will be explained in detail, down the line.
HDFS(Hadoop distributed file system) – saves the file on multiple datanodes.
The files in the Hadoop cluster will be splitted into smaller blocks and these blocks will be residing on datanodes.
Namenodes in other sides will have the information on what is the size of the files, how many blocks are residing in datanodes, and which of the datanodes this file is actually residing in?
The namenode maintains all this information in a form of a file table. So the namenode is the go to place to find the file, where it is located. We hope you're enjoying the Hadoop Tutorial so far!
Master nodes
- Name node: Central file system manager. But mind you, the namenode doesn’t save any files. All the files will be residing in Datanodes.
- Secondary name node : Data backup of name node (not hot standby)
- Job tracker: Centralized job scheduler - Slave nodes and daemons/software services
- Data node: Machine where files gets stored and processed
- Task tracker: A software service which monitors the state of job tracker
Note: Every slave node keeps sending a heart beat signal to the name node once in every 3 seconds to state that its alive. What happens when a data node goes down would be discussed down the line.
What is a job in the Hadoop ecosystem?
A job usually is some task submitted by the user to the Hadoop cluster.
The job is in the form of a program or collection of programs (a JAR file) which needs to be executed.
A job would have the following attributes to it
- The actual program
- Input data to the program (a file or collection of files in a directory)
- The output directory where the results of execution is collected in a files
Core features of Apache Hadoop
- HDFS (Hadoop Distributed File System) – data storage
- MapReduce Framework – compute in distributed environment
- A Java framework responsible for processing jobs in distributed mode
- User-defined map phase, which is a parallel, share-nothing processing of input
- User-defined reduce phase aggregates of the output of the map phase
Submitting and executing a job in a hadoop cluster
The engineer/analyst's machine is not a part of the Hadoop cluster. Usually Hadoop would be installed in pseudo-distributed mode on his/her machine. The job ( program/s ) would be submitted to the gateway machine
The gateway machine would have the necessary configuration to communicate to the name node and job tracker.
Job gets submitted to the name node and eventually the job tracker is responsible for scheduling the execution of the job on the data nodes in the cluster.
HDFS– The storage layer in Hadoop
Takes the input file from the client and Namenode(is a part of Hadoop cluster) splits the task and assigns it to Datanodes.
Splitting of file into blocks in HDFS
Default size is 64MB(it can be changed). Original file size is 200 MB. 200 MB is split into 4 blocks of N1, N2, N3 and N4.
The block N4 is just 8MB(200–64*3)
Each block is now a separate file and N1, N2, N3 and N4 are file names.
File storage in HDFS
Breaking up of the original file into multiple blocks happens in the client machine and not in the name node.
The decision of which block resides on which data node is not done randomly!
Client machine directly writes the files to the data nodes once the name node provides the details about data nodes
Failure of a data node
What happens in the event of a data node Failure ? (eg : DN 10 fails)
Data saved on that node will be lost. To avoid loss of data, copies of the Data blocks on data nodes are stored on multiple data nodes. This is called data replication.
Replication of Data blocks
How many copies of each block to save?
Its decided by REPLICATION FACTOR (by default its 3, i.e. every block of data on each data node is saved on 2 more machines so that there is total 3 copies of the same data block on different machines). This replication factor can be set on per file basis while the file is being written to HDFS for the first time.
Replica Placement Strategy
Q. How does namenode choose which datanodes to store replicas on?
- Replica Placements are rack aware. Namenode uses the network location when determining where to place block replicas.
- Tradeoff: Reliability v/s read/write bandwidth e.g.
– If all replica is on single node - lowest write bandwidth but no redundancy if nodes fails
– If replica is off-rack - real redundancy but high read bandwidth (more time)
– If replica is off datacenter – best redundancy at the cost of huge bandwidth
- Hadoop’s default strategy:
– 1st replica on same node as client
– 2nd replica on off rack any random node
– 3rd replica is same rack as 2nd but other node
- Clients always read from the nearest node
- Once the replica locations is chosen a pipeline is built taking network topology into account
Name node and secondary name node in Hadoop 1.0
Name node: I know where the file blocks are…
Secondary name node: I shall back up the data of the name node
But I do not work in HOT STANDBY mode in the event of name node failureL
Note: In Hadoop 1.0, there is no active standby secondary name node.
(HA : Highly available is another term used for HOT/ACTIVE STANDBY )
If the name node fails, the entire cluster goes down ! We need to manually restart
The name node and the contents of the secondary name node has to be copied to it.
HDFS Advantages
- Storing large files
- Terabytes, Petabytes, etc.
- millions rather billions of files (less number of large files)
- Each file typically 100MB or more
- Streaming data
- WORM - write once read many times patterns
- Optimized for batch/streaming reads rather than random reads
- Append operation added to Hadoop 0.21
- Cheap commodity hardware
HDFS Disadvantages
- Large amount of small files
- Better for less no of large files instead of more small files
- Low latency reads
- Many writes: write once, no random writes, append mode write at end of file
Hadoop Installation
In this next step of the Hadoop Tutorial, lets look at how to install Hadoop in our machines or work in a Big data cloud lab.
Please see the installation steps:
1. create EC2 instance with Ubuntu 18.04
2. Create new user, grant root permission(ALL)
sudo addgroup hadoop
sudo adduser -- ingroup hadoop hduser
sudo visudo
hduser ALL=(ALL:ALL) ALL
su - hduser
3. Install Java (Upload to /usr/local using winscp) and follow steps
MAKE SURE THAT DOUBLE QUOTES ("") ARE REPRESENTED CORRECTLY.
sudo tar xvzf jdk-8u181-linux-x64.tar.gz
sudo mv jdk1.8.0_181 java
ls
cd ~
sudo nano ~/.bashrc
export JAVA_HOME=/usr/local/java
export PATH=$PATH:/usr/local/java/bin
source ~/.bashrc
sudo update-alternatives --install "/usr/bin/java" "java" "/usr/local/java/bin/java" 1
sudo update-alternatives --install "/usr/bin/javac" "javac" "/usr/local/java/bin/javac" 1
sudo update-alternatives --install "/usr/bin/javaws" "javaws" "/usr/local/java/bin/javaws" 1
Verify Java installation
sudo update-alternatives --set java /usr/local/java/bin/java
sudo update-alternatives --set javac /usr/local/java/bin/javac
sudo update-alternatives --set javaws /usr/local/java/bin/javaws
java -version
4. Passwordless SSH, follow the steps below
ssh localhost
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
Then try ssh localhost
5. Install Hadoop from apache web site.
cd /usr/local
wget hadoop
sudo tar xvzf hadoop-3.0.2.tar.gz
sudo mv hadoop-3.0.2 hadoop
First, provide the ownership of hadoop to ‘user’ hduser [“ This will give ownership only to hduser for running hadoop services ”] using chmod & change the mode of hadoop folder to read, write & execute modes of working.
sudo chown -R hduser:hadoop /usr/local/hadoop
sudo chmod -R 777 /usr/local/hadoop
Disable IPV6
Hadoop & IPV6 does not agrees on the meaning of address 0.0.0.0 so we need to disable IPV6 editing the file…
sudo nano /etc/sysctl.conf
with…
net.ipv6.conf.all.disable_ipv6=1
net.ipv6.conf.default_ipv6=1
net.ipv6.conf.lo.disable_ipv6=1
For confirming if IPV6 is disable or not! execute the command.
cat /proc/sys/net/ipv6/conf/all/disable_ipv6
Apply changes in .bashrc file for setting the necessary hadoop environment. Setting changes with hadoop path. Locations of sbin[ “It stores hadoop’s necessary command location” ] & bin directory path are essential otherwise as user you have to always change location to hadoop’s sbin or bin to run required commands.
sudo nano ~/.bashrc
#HADOOP ENVIRONMENT
export HADOOP_PREFIX=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_HDFS_HOME=/usr/local/hadoop
export YARN_HOME=/usr/local/hadoop
export PATH=$PATH:/usr/local/hadoop/bin
export PATH=$PATH:/usr/local/hadoop/sbin
#HADOOP NATIVE PATH:
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS=“-Djava.library.path=$HADOOP_PREFIX/lib”
cd /usr/local/hadoop/etc/hadoop/
sudo nano hadoop-env.sh
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
export JAVA_HOME=/usr/local/java
export HADOOP_HOME_WARN_SUPPRESS=”TRUE”
export HADOOP_ROOT_LOGGER=”WARN,DRFA”
sudo nano yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
sudo nano hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/yarn_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/yarn_data/hdfs/datanode</value>
</property>
sudo nano core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
sudo nano mapred-site.xml
<property>
<name>mapred.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>localhost:10020</value>
</property>
sudo mkdir -p /app/hadoop/tmp
sudo chown -R hduser:hadoop /app/hadoop/tmp
sudo chmod -R 777 /app/hadoop/tmp
sudo mkdir -p /usr/local/hadoop/yarn_data/hdfs/namenode
sudo mkdir -p /usr/local/hadoop/yarn_data/hdfs/datanode
sudo chmod -R 777 /usr/local/hadoop/yarn_data/hdfs/namenode
sudo chmod -R 700 /usr/local/hadoop/yarn_data/hdfs/datanode
sudo chown -R hduser:hadoop /usr/local/hadoop/yarn_data/hdfs/namenode
sudo chown -R hduser:hadoop /usr/local/hadoop/yarn_data/hdfs/datanode
hdfs namenode -format
start-dfs.sh
start-yarn.sh
6. In setting the Hadoop Environment section,
#HADOOP NATIVE PATH:
export “HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS=“-Djava.library.path=$HADOOP_PREFIX/lib”
Make sure that HADOOP_COMMON_LIB_NATIVE_DIR has no double quotes.
7. In hadoop-env.sh make sure double quotes are intact.
8. While creating a datanode directory, make sure that the permissions are 700.
9. start daemons. check namenode web UI at 9870. check resource manager web ui.
Once the installation is successfully done, we can play with some UNIX commands(better to have a touch on basics)
Basic knowledge on UNIX commands is required for us to navigate throughout our file system. Hope you're keeping up with the Hadoop Tutorial so far!
HDFS- Basic commands
Let us see how:
Pwd – present work directory
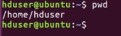
Here hduser is the name of the user
‘/’ is root.
- To navigate to root directory,

- To list all the contents:

For demonstrating HDFS commands, we need to first start all the Hadoop services. Since Hadoop is installed in sudo distributed mode, all the Hadoop components, the namenode, secondary namenode, the job tracker (resource manager in Hadoop 2.0).
We will run the built in script.
start-all.sh
Type the command and wait for a while

When the Hadoop service starts by default, the Map reduce engine is up and running and the HDFS is up and running.
See the messages above(for clear understand)
- Now how to check if all these services are running?
Type in the command called jps – which lists the java processes on the system.
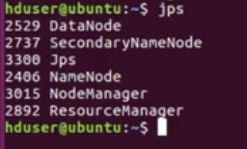
The numbers are process ids for each process(can be ignored)
- To see what is there in the home directory of my Hadoop file system, we cannot use the ‘ls’ command. We use the below command
hadoop fs –ls

- Now, to see where exactly this sample is stored?

- How to make a directory in HDFS?
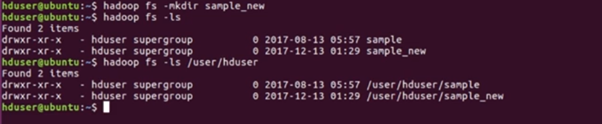
- To delete files from HDFS
Suppose there are 2 file above sample and sample_new
Ex: to remove ‘sample_new’ folder see below.
- To copy a file from a local file system to Hadoop file system.
Here, ‘samplefile.txt’ is a small file in local file system and ‘sample101’ is the destination folder

- To see the content of the file, here(samplefile.txt)

Note: This command is not recommended to see the content of big data file in a Hadoop cluster
Mapreduce: A Programming Paradigm
As we now know Hadoop comes with 2 important components, HDFS(storage) and Mapreduce(processing)
- A Java framework for processing parallelizable problems across huge datasets, using commodity hardware, in a distributed environment
- Google has used it to process its “big-data” sets (~ 20,000 PB/day)
- Can be implemented in many languages: Java, C++, Ruby, Python etc.
Even Apache Spark uses, mapreduce approach of processing so the idea is going to be useful to understand spark as well. Hold it, we will learn Spark in detail.
Now let us understand the basic logic of map reduce by looking at the wordcount problem.
Problem statement: To count the frequency of words in a file.
Input file name: secret.txt and has just 2 lines of data. Contents of the file: this is not a secret if you read it
it is a secret if you do not read it
THE EXPECTED OUTPUT AS BELOW
This 1
is 2
not 2
a 2
secret 2
if 2
you 2
do 1
read 2
it 2
The mapreduce framework, as the name implies, it is a two stage approach, within 3 stages, we have substages.
In the Map stage, the first sub-stage is the Record reader and it will read the program line by line. See the demonstration below.
Stage 2: Approach using Map and Reduce:
THE MAP STAGE
this is not a secret if you read it
(The above is the first line in the input file)
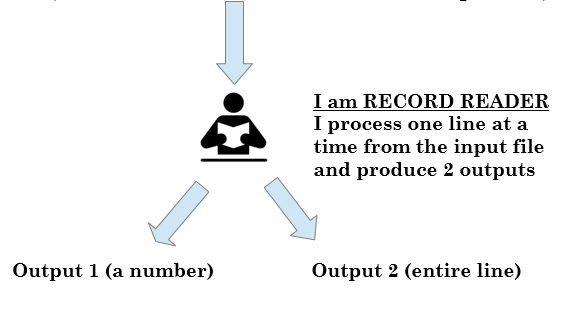
Now, for the sake of naming conventions, we will choose the term called as key to refer to the output 1 and value to refer to the Output 2.
Output of the record reader
Output 1 (A number), Output 2 (The entire line)
Output 1 is always called as KEY
Output 2 is always called as VALUE
(The same naming conventions would be used throughout the discussion hereafter)
KEY: 0 (file offset)
VALUE: this is not a secret if you read it (first line)
To understand, what exactly is the idea of line offset in a file is:
Consider this file having 2 lines
It’s a new file
Which is almost used for nothing !
Each character in the file occupies one byte of data
First character of line one starts at location 0
Number of characters in the first line
It’s: 4 space: 1 (total 5)
a: 1 space: 1 (total 2)
new: 3 space: 1 (total 4)
file: 4 new line:1 (total 5)
Total of 16 characters or 16 bytes. The next line would begin at location 17. File offset for next line is 17.
Record reader’s Output to the mapper
0 (KEY) this is not a secret if you read it (VALUE)
MAPPER can be programmed and accept only one key value pairs as input and produce key-value-pairs as output
- Mapper can process only one key & value at a time
- Produce output in key, value pairs based on what its programmed to perform
Programming the Mapper:
- Mapper can be programmed based on the problem statement
- The input is a key value pair (file offset, one line from file)
0, this is not a secret if you read it
In the word count problem we shall program the mapper to do the following
Step1 : Ignore the key (file offset)
Step 2: Extract each word from the line
Step 3: Produce the output in key value pairs where key is each word of the line and value as 1 (integer/a number)
Output of the Mapper:
0, this is not a secret if you read it.
this 1
is 1
not 1
a 1
secret 1
if 1
you 1
read 1
it 1
The sort operation
Output of the mapper is fed into the sorter which sorts the mapper output in ascending order of the KEYS! (lexicographic ordering or dictionary ordering since the keys are of string type)
Note : Sorter can be reprogrammed (overridden) to sort based on values if required. Its called the sort comparator.
Input to the SORT phase:
this 1
is 1
not 1
a 1
secret 1
if 1
you 1
read 1
it 1
it 1
is 1
a 1
Output of the sort phase
a 1
a 1
do 1
if 1
if 1
is 1
it 1
it 1
it 1
not 1
not 1
read 1
read 1
secret 1
REDUCE STAGE:
It has 3 sub-stages - merge, shuffle and reducer operation
The output of the several mapper's will be merged into a single file at reduce stage
SHUFFLE/aggregate phase in REDUCE stage:
Shuffling is a phase where duplicate keys from the input are aggregated.
Consider the simple example
Input is key value pairs (contains duplicate keys)
Output is a set of key value pairs without duplicate
| Key | Value |
| Apple | 2 |
| Apple | 4 |
| Mango | 1 |
| Orange | 11 |
| Orange | 06 |
| Key | Value |
| Apple | 2, 4 |
| Mango | 1 |
| Orange | 11, 6 |
So the Shuffle operation at the reduce stage
a 1
a 1
do 1
if 1
if 1
is 1
is 1
it 1
it 1
a 1,1
do 1
if 1,1
is 1,1
it 1,1
The REDUCER operation in REDUCE stage
Reducer accepts the input from the shuffle stage
Reducer produces output in key value pairs based on what it is programmed to do as per the problem statement
Programming the reducer
Output of the shuffle is the input to the reducer
Reducer can handle only one key value pair at a time
Step 1: Input to the reducer is a 1, 1
Step 2: The reducer must add the list of values from the input i.e
sum=1+1 = 2
Step 3: Output the key and sum as output key, value pairs to an output file. The o/ would look like a 2.
Step 4: Repeat the above operations (1,2&3) for entire input
Final output of the Reducer:
a 1,1
do 1
if 1,1
is 1,1
it 1,1,1
not 1,1
read 1,1
secret 1,1
this 1
you 1,1
Reducer output(final o/p)
a 2
do 1
if 2
is 2
it 3
not 2
read 2
secret 2
this 1
you 2
Summary
As we're coming to the end of our Hadoop Tutorial, let us summarize. Input file processed by record reader output goes to MAPPER and its output is sorted
Closer look to Map reduce
Map-Reduce Approach to Anagram Problem:
Identifying the Anagrams in a Text file:
What are anagrams?
MARY is a word and ARMY is another word which is formed by re arranging the letters in the original word MARY
• MARY and ARMY are anagrams
• POOL and LOOP are anagrams. There could a lot of such examples.
Note: We are interested in finding out anagram combinations from a text document which does not contain irrelevant gibberish words
Problem Statement:
To identify and list all the anagrams found in a document. Eg A book (a novel)
Input file name: sample.txt (a file in text format) and has 2 lines in the file.
File contents: mary worked in army
the loop fell into the pool
Expected output: (must contain all the anagrams)
mary army
loop pool
Output of record Reader:
This is going to the be output of the record reader after reading the first line of the file
Contents of the file:
mary worked in army
loop fell into the pool
| KEY | VALUE |
| file offset | entire line of the file |
| 0 | Mary worked in army |
The above (key-value pair) is now going to be fed into the mapper as an input.
Programming the Mapper
Mapper is programmed do the following
Step 1: Ignore the key from the record reader
Step 2: Split the words in the value (the full line)
mary works in army
[mary] [works] [in] [army] (the line is split)
Step 3: Compute the word length of each word
Step 4: Output the word length as key and original word as value . The sample output of mapper would look like-
| Key | Value |
| 4 | Mary |
| 5 | works |
| 2 | in |
Step 5: Repeat the above steps for all the words in the line
Output of the Mapper after Processing the Entire file.
| Key | Value |
| 4 | mary |
| 6 | worked |
| 2 | in |
| 3 | the |
| 4 | army |
| 4 | loop |
| 4 | fell |
| 4 | into |
| 3 | the |
| 4 | pool |
Output after sorting the keys:
KEY VALUE
2 in
3 the
3 the
4 mary
4 army
4 loop
4 fell
4 into
4 pool
6 worked
This is the Output to the Reducer:
KEY VALUE
2 in
3 the, the
4 mary , army , loop, fell , into, pool
6 worked
What can we do in the Reducer now to identify the Anagrams?
KEY VALUE
2 in
3 the, the
4 mary , army , loop, fell , into, pool
6 worked
• Pick one word at a time from the list of values for every key value pair
• Check if the same combination of letters are present in every other word in the list
i.e, the letters m,a,r and y is present in amry, if true then mary and army are anagrams
• How to revolve the and the as both contain the same combination of alphabets ?
Its simple, we can choose do a string comparison and if the strings are identical then we can ignore them!
Problem with this Approach
• This looks like a solution however has several challenges
• Consider the below key value pair
4 mary, army, loo, fell, into, pool
• To compare the alphabet combinations m,a,r and y is present in one other word takes 4 X 4 = 16 comparisons
• 16 comparison operation multiplied by number of words in the value list = 16 X 6 = 96 comparison operations
• What is the list it too long? This just worsens the computation time in the event of large data sets (big data)
• Reducer is overloaded here!
• What seemed as a solution, is not so practical approach for BIG DATA set
The Alternate approach would be as follows
Output of the Record reader
This is going to the be output of the record reader after reading the first line of the file
Contents of the file: mary worked in army
loop fell into the pool
| Key | Value |
| file offset | entire line of the field |
| 0 | mary worked in army |
The above (key-value pair) is now going to be fed into the mapper as an input.
Programming the Mapper:
Mapper is programmed do the following
Step 1: Ignore the key from the record reader
Step 2: Split the words in the value (the full line)
mary works in army
[mary] [works] [in] [army] (the line is split)
Step 3: sort each word in dictionary order (lexicographic ordering)
mary after sorting would become amry
Step 4: Output the sorted word as key and original word as value . The sample output of mapper would look like
| Key | Value |
| Army | Mary |
Step 5: Repeat the above steps for all the words in the line
Output of the mapper after processing the entire file
| Key | Value |
| amry | mary |
| dekorw | worked |
| in | in |
| eht | the |
| amry | army |
| loop | loop |
| efll | fell |
| eth | the |
| loop | pool |
Output after sorting the keys
| Key | Value |
| amry | mary |
| amry | army |
| dekorw | worked |
| eth | the |
| in | in |
| inot | into |
| loop | loop |
| loop | pool |
| efll | fell |
Output after shuffling the keys(aggregation of duplicate keys)]
| Key | Value |
| amry | mary, army |
| dekoew | worked |
| eht | the, the |
| in | in |
| inot | into |
| loop | loop, pool |
| efll | fell |
LOOK CLOSER!
There are some keys with more than one value. We need to only look at such key, value pairs
amry mary, army
eht the, the
loop loop, pool
Logic to list the anagrams
amry mary, army
eht the, the
loop loop, pool
Problem : We need to only print the values belonging to keys “amry” and “loop” since only their values qualify for anagrams.
We need to ignore the values belonging to the keys “eht” since its corresponding values do not qualify for being anagrams.
How to ignore the non-anagram values?
amry mary, army
eht the, the
loop loop, pool
We need to program the following into the reducer
Step 1: Check if the number of values are > 1 for each key
Step 2: Compare the first and second value in the values list for every key, if they match, ignore them.
key val1 val2
eht the the
Step 3: If the values don’t match in step 2. Compose a single string comprising of all the values in the list and print it to the output file. This final string is the KEY and value can be NULL (do not print anything for value)
KEY = “mary army” VALUE =“ “
Step 4: Repeat the above steps for all the key value pairs input to the reducer.
Final Output of the Reducer?
mary army
loop pool
The above output is for the case of a file with just 2 lines of data.
What if the file is 640MB in size?
How does map reduce help in speeding up the job completion?
How does Map reduce speed up the processing?
What is the input file used in this example is 640MB instead of just containing 2 lines ?
• The HADOOP framework would first split the entire file into 10 blocks each of 64MB
• Each 64MB block would be treated as a single file
• There would be one record-reader and one mapper assigned to each such block
• Output of all the mappers would finally reach the reducer (one reducer is used by default) however we can have multiple reducers depending on degree of optimization required
Why Map Reduce?
• Scale out not scale up: MR is designed to work with commodity hardware
• Move code where the data is: cluster have limited bandwidth
• Hide system-level details from developers: no more race condition, dead locks etc
• Separating the what from how: developer specifies the computation, framework handles actual execution
• Failures are common and handled automatically
• Batch processing: access data sequentially instead of random to avoid locking up
• Linear Scalability: once the MR algorithm is designed, it can work on any size cluster
• Divide & Conquer: MR follows Partition and Combine in Map/Reduce phase
• High-level system details: monitoring of the status of data and processing
• Everything happens on top-of a HDFS
Use Case of MapReduce?
• Mainly used for searching keywords in massive amount of data
• Google uses it for wordcount, adwords, pagerank, indexing data for Google Search, article clustering for Google News
• Yahoo: “web map” powering Search, spam detection for Mail
• Simple algorithms such as grep, text-indexing, reverse indexing
• Data mining domain
• Facebook uses it for data mining, ad optimization, spam detection
• Financial services use it for analytics
• Astronomy: Gaussian analysis for locating extra-terrestrial objects
• Most batch oriented non-interactive jobs analysis tasks
Now that we know the flow of map reduce using an example of word count and Anagram problem using map reduce, See the source code in the link below from the documentation to get a practical approach.
Now that we have discussed two examples that are Wordcount frequency and Anagram problem, let's quickly take a practical approach to understand what a java map reduce program would look like.
Note: For the detailed java code explanation, please refer to the above link.
Also, we will have a look at map reduce commands only as we already learnt about HDFS command.
Step 1: Create a small folder in which a text file is stored(input file) in a local file system and put in HDFS folder(keep this set up ready)
Step 2: You can run the java program in Eclipse(IDE)
Step 3: In the root folder, inside the folder, we can see the jar file, the jar file consists of all the 3 source code of java files from eclipse and get an executable file (example : wc_temp.jar)
Step 4: Now let us run this jar file on a cluster. Open the terminal, and make sure all the Hadoop services are running in the background. Check if the input file is there in the HDFS.
Step 5: Command to execute the jar file, first navigate to the folder where the jar file is located.
Command to deploy the jar file on Hadoop cluster is:

Here, WordCountDrivername - name of the driver code
wcin/sampledata.txt-name of the input file path
wcout_demo-Destination HDFS folder
Step 6: Once the execution is done, if the output folder has been created.
Then if the program is successfully completed, you must see the below output.

You can see the output file in the destination folder.
HADOOP 2.0 – Introducing YARN
YARN – Yet another resource negotiator
YARN (Hadoop 2.0) is the new scheduler and centralized resource manager in the cluster.
∙ It replaces the Job tracker in Hadoop 2.0
∙ The started back in 2012 as an apache sub project and a beta version was released in mid 2013 stable versions became available from 2014 onwards
YARN(80)
Components of YARN(80)
It's a 2 tiered model with some components (demons) in master mode and some operating in slave mode.
Resource manager works in master mode (runs on a dedicated hardware in production setup
Node manager works in slave mode & its services are run in the data nodes.
Resource manager comprises of 2 components
1)Scheduler
2)Applications Manager
Node manager consists of a container (an encapsulation of resources for running a job) and an app Master (application master).
Also Read: Top 40 Hadoop Interview Questions
Hadoop 1.0 vs Hadoop 2.0(80)
Hadoop 3.0