


Amazon Web Services is a gold standard in the Cloud market with 250+ services to boast of. Amazon S3 is one AWS Storage service that is widely used and loved in the cloud market. In this article, we will explore and understand Amazon S3 in detail.
Following pointers will be covered in this article,
- What is Amazon Web Services?
- AWS Cloud Storage
- What is Amazon S3?
- What is Amazon S3 Versioning?
- Lifecycle Management in Amazon S3
- When to Use Lifecycle Management?
So let us get started with the first topic in hand,
What is Amazon Web Services?
Amazon Web Services as mentioned above is the gold standard or easily the best Cloud Service provider in the public cloud domain. It provides on-demand Cloud Computing services, that can be rented on metered usage and can be accessed across the globe by using the internet. Here Amazon Web Services takes care of managing and monitoring resources so one as a consumer does not have to invest too much time in doing these activities. It provides services in the following domains:
- Computation
- Storage
- Databases
- Security
- Networking
- Monitoring
- Messaging
- Migration
- Machine
Learning - DevOps
- IoT, etc
It serves in 245+ countries and offers 250+ services. It provides following features,
- Scalability
- Availability
- Metered
Usage - Flexibility
- Durability,
etc
So this was about Amazon Web Services, let us now go ahead and understand how AWS Storage works,
AWS Cloud Storage
Cloud storage is nothing but an ability given to you as an individual to store your data on Cloud. Cloud storage lets you store data that can be,
- Files
- Pictures
- Processing
Data - Messages
- Logs
- Videos, etc
Cloud storage lets you store data at an affordable price and lets you take data backups ensuring your data is safe and secure on cloud. This data can be processed making sure you can put your data to use on top of Cloud.
Amazon Web Services provides plenty of services that help you store data safely in secure manner on AWS Cloud Platform. It provides following storage services,
- Amazon EBS
- Amazon S3
- Amazon EFS
- Amazon Glacier
- Amazon
Storage Gateway - Amazon
Snowmobile - Amazon
Snowball etc,
Amazon mostly classifies it storage in Block, Object and file kind of storage. Following image shows those kinds of storages.
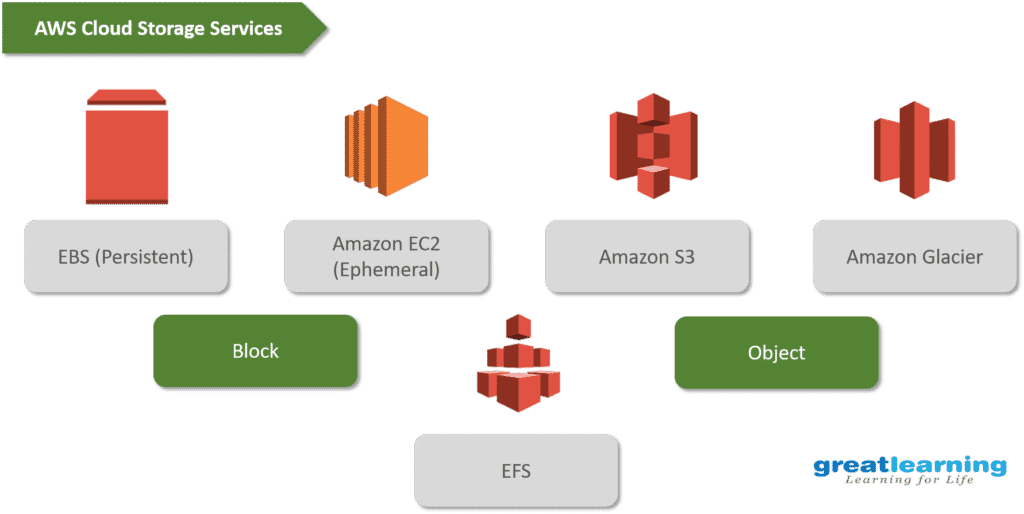
EBS
Also known as Elastic Block Store it is storage that comes I block form. In order to use storage. You have to attach it to a host virtual machine. It is similar to a hard disk drive where the storage can only be used when it is attached to a system or a laptop.
This is persistent storage that means of the system goes down the storage will still be available and can be used later when attached to a machine.
Amazon EC2 Ephemeral Storage
This is also block store but this volume or storage goes away with the instance. That means if the instance is terminated the storage also gets deleted by default.
Amazon Glacier
This is a type of archival storage that means we store that data which is not used frequently. Say for example data files that very rarely accessed. For example, hospital record, like birth certificates. This storage is hence called as cold storage. Since this data is not frequently used. We store it in cold storage something we refrain from accessing every now and then. It is cheaper and hence affordable.
EFS
EFS stands for Elastic File System and as the name suggests is used for Storing file data or managing file systems.
Amazon Snowball
This storage is used for moving data physically. Think of it as more of a Pendrive or Hard disk drive that can be used to move your data physically from one data centre to another.
What if the amount of data to be moved is large in size? In that case, we can use Amazon Snowmobile. Amazon Snowmobile lets us move heaps of data from one data centre to another physically.
In this article, we will be exploring Amazon S3 in detail. So let us go ahead and understand Amazon S3,
What is Amazon S3?
Amazon S3 is Cloud Storage offered by AWS. Amazon S3 support object storage and is hot storage in nature. Let us understand Cold and hot storage first.
Cold Storage
This is kind storage as the name suggests is cold or slow in nature. That means if you store your data here, it will take 4-48 hours for you to retrieve your data at least. This data storage is affordable or cheaper. It is used by applications where data retrieval is not critical and data latency won’t impact the business in general.
Hot Storage
Hot storage is as you might have guessed a storage that lets you retrieve data faster and is reliable in terms of processing data retrieval latency free. Amazon S3 is hot cloud storage and is hence costlier because you get faster data retrieval.
Let us now go ahead and understand components of S3 storage service,
Amazon S3 Buckets
In order to store your data in Amazon S3, you would need a container that can hold this data. These containers with respect to Amazon S3 are known as Buckets
Amazon S3 Objects
Amazon S3 objects are nothing but files that we store in the Amazon S3 bucket. Please not Amazon S3 is a key value store. You can store as many object these in these buckets you want. These object can be as big as 5tb in size.
Key: The name you assign to the object
Version: It is the version Id of a specific version of a file. We will explore this in detail some of the following topics. The version helps uniquely identify a particular object.
Value and Metadata: Value is nothing but a concept we are trying to store. Whereas Metadata is the information about the data we are trying to store
With S3 we can create multiple buckets in Different AWS regions and store or transfer our data there.
So this was about the fundamentals of S3. Let us now go ahead and understand what Versioning is and how it works
What Is Amazon S3 Versioning?
Data Backup and Data Recovery are two processes where companies invest a lot of money to preserve their data against unwanted hazards. While storing your data, you may have concerns where you may feel you want to avoid overwriting of files. In case if you do you may lose that data and it would be difficult for you then to backtrack and recover that data.
With Amazon S3 you have an option of versioning. That means you can maintain multiple copies of your data in the same bucket. To give you a simple example let us assume you have a file saved in Amazon S3. Now you go ahead and save the same file on Amazon again. You will get the latest copy of the file you stored. But if you have activated the versioning option in S3 then if you click on the object then all the previous versions of the file will be available and you can then backtrack to previous and use it or make whatever necessary changes you feel you need to implement.
This feature as mentioned above is very handy when it comes to storing data and preserving all its versions. So this was about versioning in Amazon S3. Let us go ahead and understand another feature that helps us optimize costs for versioning and also lets us optimize costs in general.
Lifecycle Management In Amazon S3
S3 offers different pricing tiers, to users based on how frequently objects in the bucket are accessed. The frequent is the access of objects, the more S3 charges you. That is understandable because the more frequently you access the data the faster retrieval is needed and hence AWS charges you more there.
Amazon S3 offers three tiers, that is Frequently Accessed, Infrequently Accessed and Glacier. So in order to manage these objects better and ensure that they do not incur additional costs to us and we can continue to use them optimally, we can go ahead and apply lifecycle policy to them.
Lifecycle policies are nothing but a set of rules that are applied to objects in a bucket. These are of two types,
Transition Actions: Transition actions tell you when objects transition to another storage class. For example, after a certain period of time say 15-30 days you may want to transfer your data Standard Infrequently accessed data group if your objects are not being accessed frequently.
The other type is,
Expiration Actions:
There is a certain set of objects you would not want to use after a certain duration. So you can go ahead and define when you want these objects to expire. These are called as expiration actions.
When to Use Lifecycle Management?
- Logs uploaded to bucket whose requirement may be less than a week
- Objects that may not be accessed frequently after a limit. So moving them to Infrequently accessed storage
- Dealing with Archival Data that may not be accessed for a duration, ex: HealthCare records
This was about Amazon S3 lifecycle management. Let us now go ahead and Cross Region Replication
Cross-Region Replication
To understand Cross-Region Replication. It is important we understand the concept of Availability first. With Amazon Web Services being a cloud platform, it is easy for people to question security. Because there has always been a myth that data on the cloud is not secure.
What people also expect is that the data should always be available for people to use. To give you an example, Netflix is a streaming company that streams video content across the globe seamlessly.
One good feature of Netflix is that it is always available and it is rare that audiences experience downtime. This is because the data is available. How does Netflix achieve this?
They use replication capabilities that let Netflix replicate their data at different locations. That means if one of the data centres goes down, a copy of data is always available somewhere else.
When it comes to S3 people also expect the data to be always available. That means they want the data to be replicated at a location that is miles away, ensuring that if one the region goes down, a copy of it is always available at a distant location. This helps save data from:
- Outages
- Natural
Calamities
Amazon S3 supports cross-region replication that ensures that our data is safe. Once you enable Cross-Region Replication with a particular bucket, its data gets replicated in a bucket that is located in some other region. To implement this feature, you need to ensure that versioning activated on your bucket.
By now we have successfully explored some of the major concepts that Amazon S3 has to offer to us. Let us now go ahead and implement some of the concepts we saw above, practically. To do that you would be needing an Amazon Free Tier account. If you don’t have one just go ahead and get one created.
Create S3 File Versions
In this demo, we will be creating multiple versions of a file and store those in a bucket. So let us get a start:
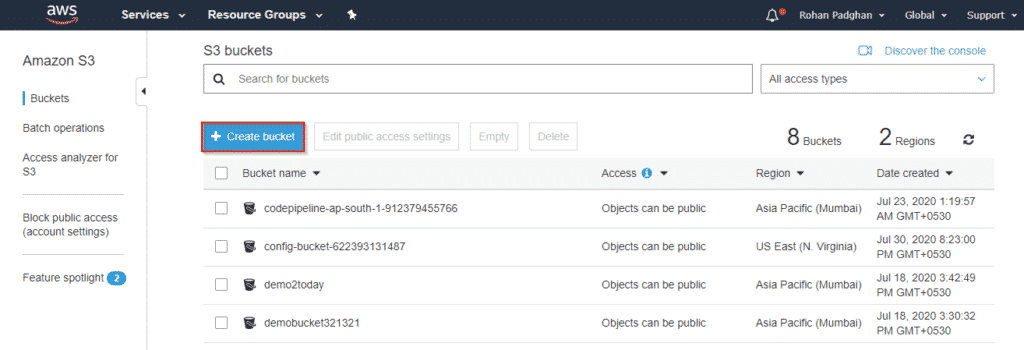
Step1: Go to AWS management Console and Open S3 Service. The following page should be on display, click on create bucket.
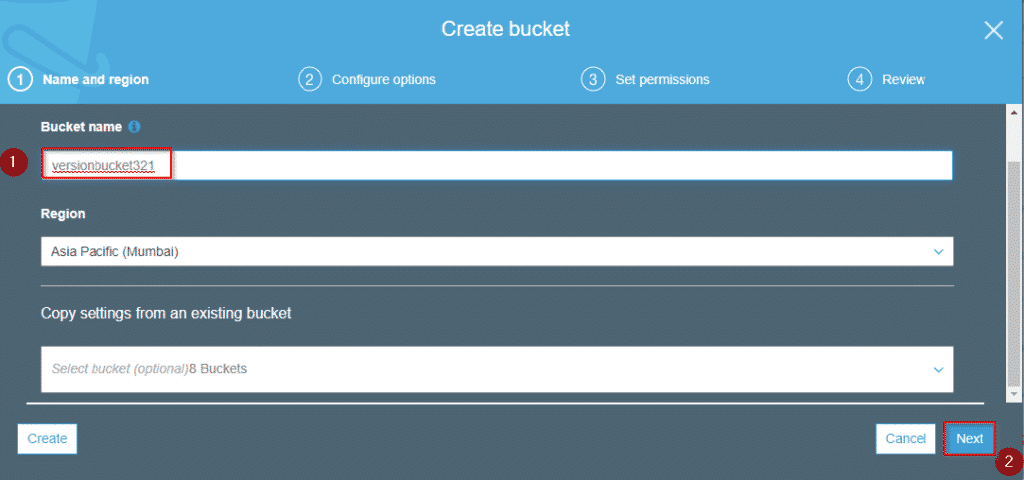
Step2: Enter a bucket name that is unique. And click on next.
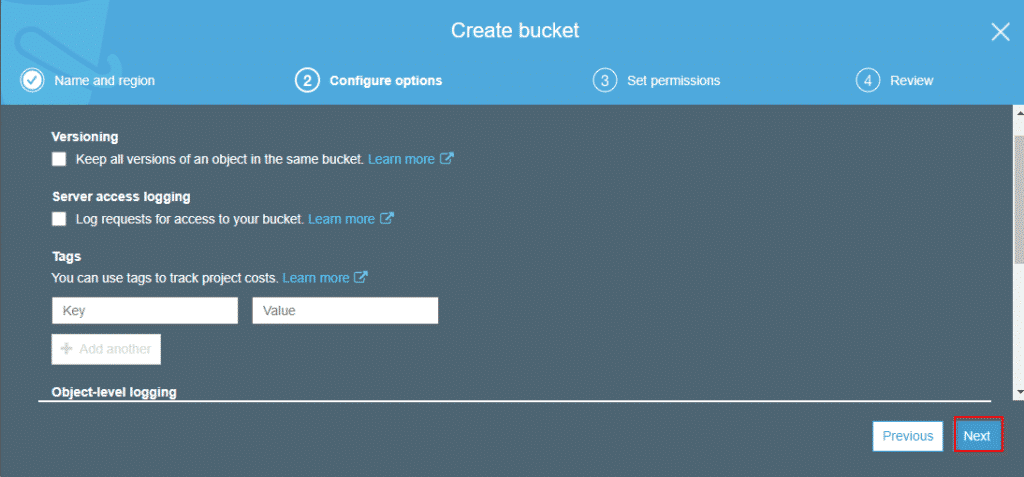
Step3: You activate versioning right away or may keep it for later as well.
Step4: Bucket policy tab lets you decide what access you for the bucket. By default, all public access to bucket is blocked. So let that be so and click on Next
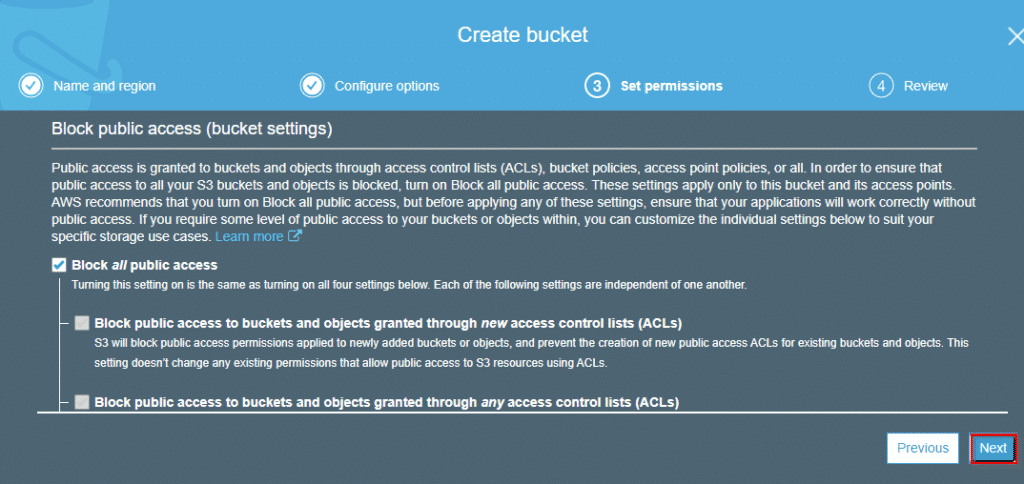
Step5: Overlook all the settings at a glance and click on create bucket
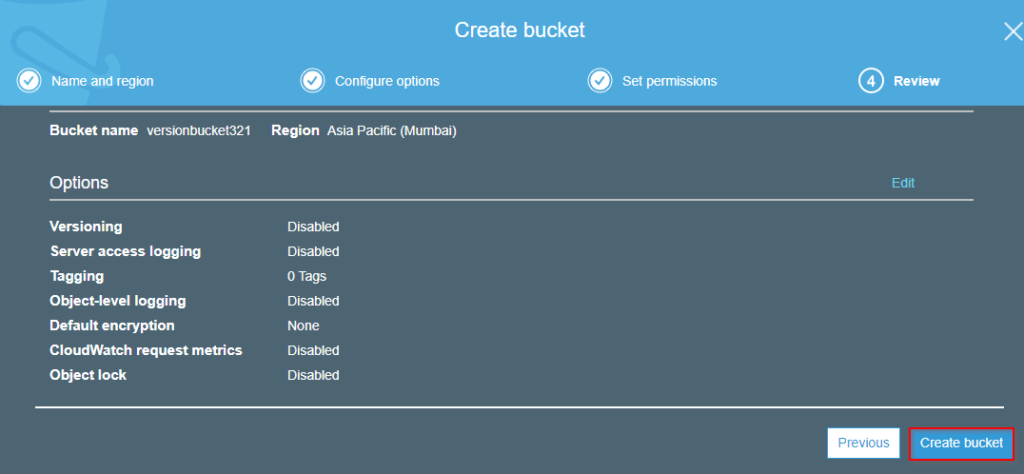
Step6: Open the bucket and click on properties.
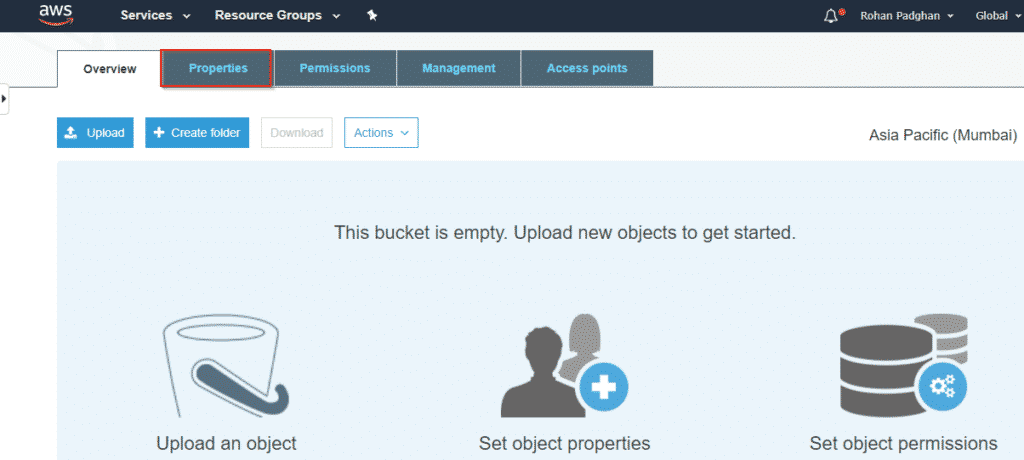
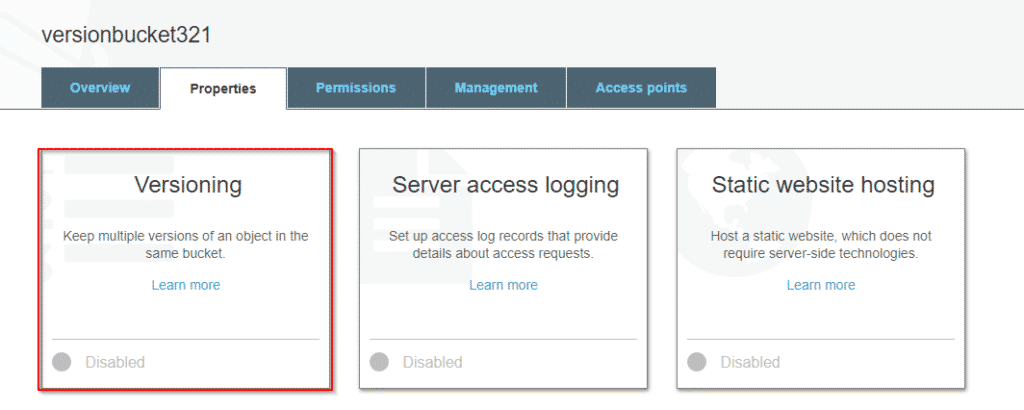
Step7: Select versioning and enable it. And go back to the bucket we created.
Step8: Click on Upload and upload a file.
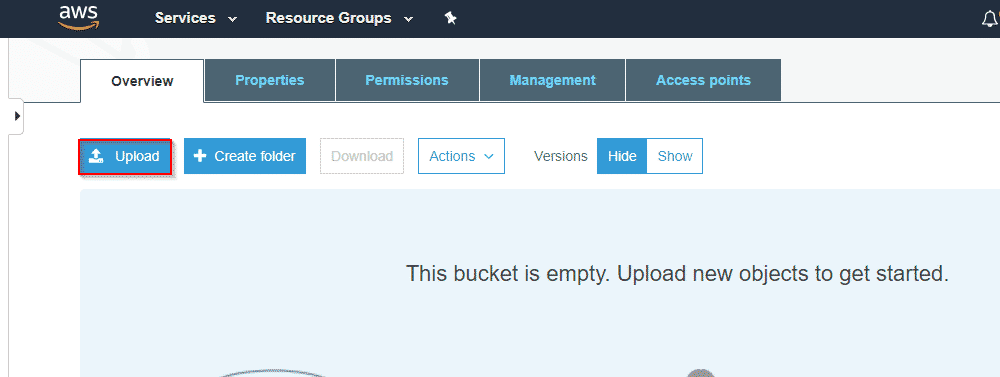
Step9:
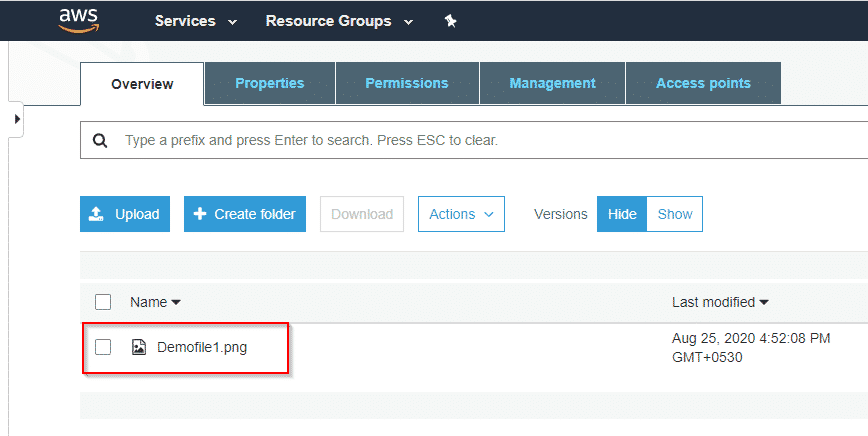
Step10: Then go ahead and upload the same file again. You will the time of the file has changed but the name of the file remains the same.
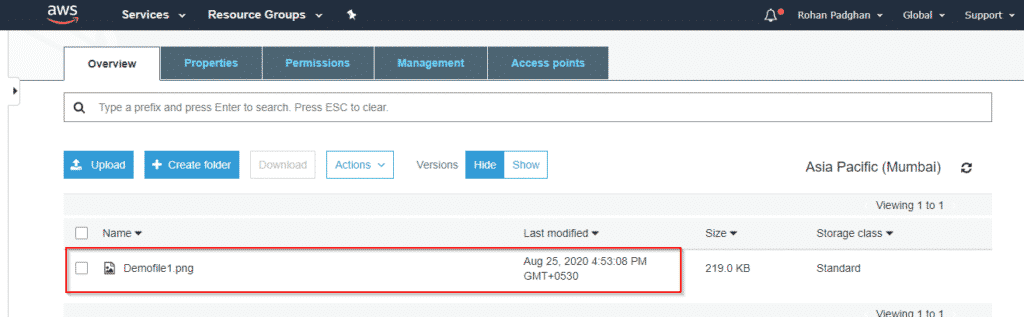
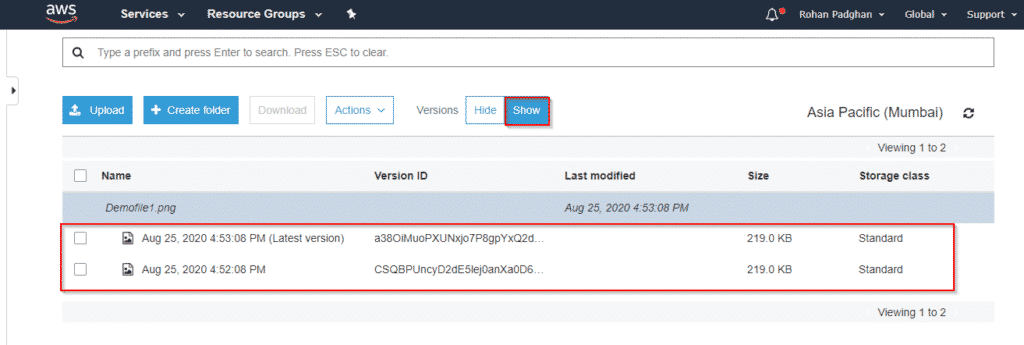
Step 11: Select the file and select the option show versions.
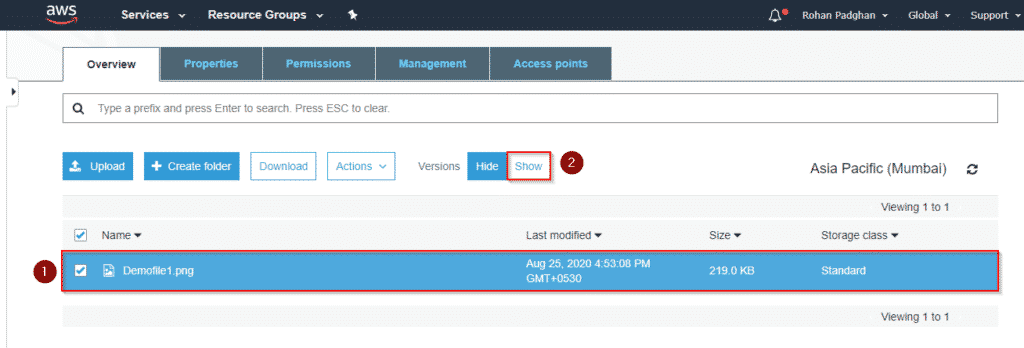
Step 12: Both versions will be displayed and you have the option of working or choosing one. This is what versioning lets you do. Hence we have successfully enabled versioning on our bucket.
This brings us to the end of this article on Amazon S3. We hope you have understood Amazon S3 and all its features. We hope you continue your journey towards learning Amazon Web Services and Cloud Computing. In case you have questions related to above-mentioned topics, then please put those in the comments section below and our team would revert to you with an appropriate answer at the earliest. Happy Learning!





