Machine Learning Modelling
Take up free machine learning modelling course and use the expertise in real-world problems.

Ratings
Level
Learning hours
Learners

Skills you will learn
About this course
Machine Learning (ML) is an Artificial Intelligent (AI) suite that deals with training a machine to self-learn and carry out the processes from previously trained inputs. The philosophy behind machine learning is that the machines can learn from sample data, recognize patterns, and make independent decisions without or with minimal human intervention. Most industries with a large amount of data use machine learning models to work efficiently, and it also helps them take over their competitors. Industries such as Oil and Gas, Health Care, Government, Financial Services, Retail, Transportation, etc., use machine learning technology.
Machine learning models are the mathematical engine for artificial intelligence. It helps to make predictions faster than humans. The machine learning modelling is the output of the training process. In this course, you will learn different types of machine learning models such as Linear Regression, Logistic Regression, and Naive Bayes models using the hands-on. It will help you understand different types of machine learning models and use them in real-world problems.
Check out our PG Course in Machine learning Today.



Course Outline
 UPGRADE
UPGRADE
Recommended university programs


MIT Professional Education
12 Weeks • Online



McCombs School of Business at The University of Texas at Austin
7 months • Online

McCombs School of Business at The University of Texas at Austin
7 months • Online

McCombs School of Business at The University of Texas at Austin
6 months • Online







What our learners enjoyed the most
Skill & tools
62% of learners found all the desired skills & tools
Frequently Asked Questions
Will I receive a certificate upon completing this free course?
Is this course free?
What is ML Modeling?
Machine Learning modeling is a file that has been trained to identify certain types of patterns.
What are the different Machine Learning Models?
There are different types of models in Machine learning, such as linear regression, graphic model, classification, decision trees, random forest, deep learning, neural networks, etc.
What machine learning model should I use?
It depends upon particular points :
-
The quality, size, and nature of the data
-
Available computational time
-
The urgency of the tasks
-
What do you want or need from the data
Become a Skilled Professional with Premium Courses
Gain work-ready skills with guided projects, top faculty and AI tools, all at an affordable price.
AI & Data science







.jpg)

english for study abroad



Recommended Free Machine Learning courses




Similar courses you might like


Related Machine Learning Courses
-

Johns Hopkins University
Certificate Program in AI Business Strategy10 weeks · Online
Know More
-
Walsh College
MS in Artificial Intelligence & Machine Learning2 Years · Online
Know More
-
MIT Professional Education
No Code AI and Machine Learning: Building Data Science Solutions12 Weeks · Online · Weekend
Learn from MIT FacultyKnow More




Relevant Career Paths >


")
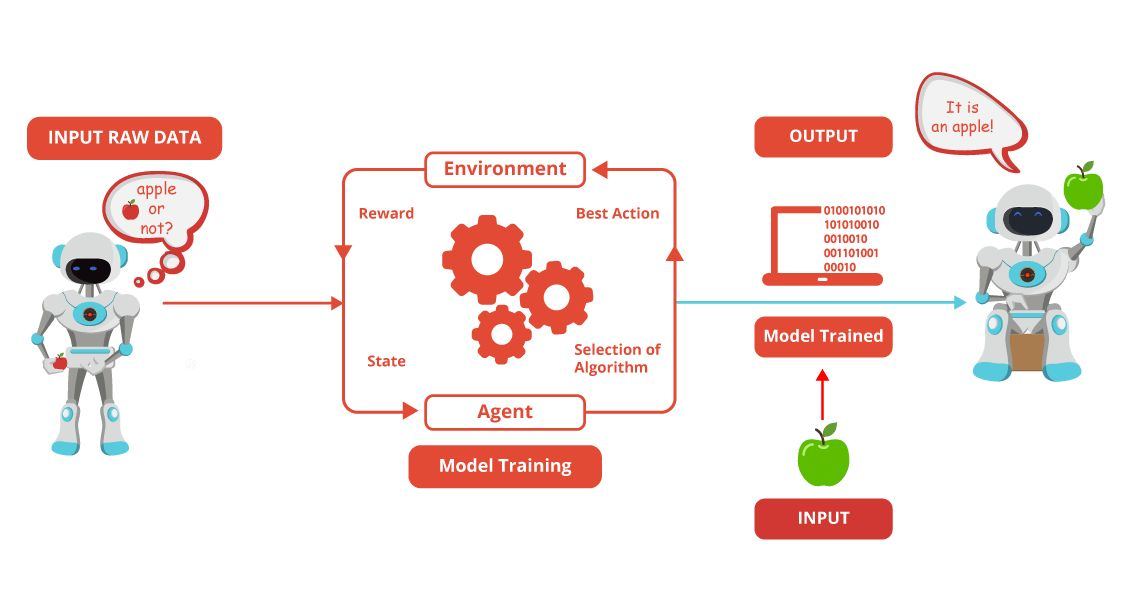
Machine Learning Modelling
What is Machine Learning?
The term Machine learning was coined by Arthur Samuel, a pioneer in artificial intelligence and computer gaming. According to Arthur Samuel, machine learning is – “Field of study that gives computers the capability to learn without being explicitly programmed.”
In layman language, machine learning improves the automating process by making computer learns from experience without human interventions.
A Brief Taxonomy of ML Models
|
ML Model Type |
Uses Cases |
|
Linear regression / Classification |
Patterns in numeric data, such as stock market prediction |
|
Graphic models |
Fraud detection or sentiment awareness |
|
Decision trees / Random forests |
Predicting outcomes |
|
Deep learning Neural networks |
Computer vision, natural language processing (NLP), and more |
Types of Machine Learning Models
Based on tasks, we can define different types of Machine Learning Models :
1. Classification Models: Classification is used to define the class or type of an object. In the classification model, the output variable is always a categorical variable. Such as predicting whether the email is spam or not. Here are different types of classification algorithms.
-
Naïve Bayes : It is based on Bayes Theorem
-
SVM: SVM or Support Vector Machine is used for binary or multiclass classification.
-
Decision Tree: A decision tree produces a sequence of rules used to classify the data.
-
Logistic Regression: Linear model for binary classification
-
K-Nearest Neighbors Algorithms: A lazy learning algorithm does not construct the general internal model. The classification is calculated by the majority of k nearest neighbor of each point.
2. Regression: In a regression model, the output variable can have a continuous value, for example, predicting stock prediction. Here are some important regression models.
-
Linear Regression: It is used to predict the value of a variable known as a dependent variable. It is predicted based on another variable known as the independent variable.
-
Lasso Regression: It is a linear regression with L2 regularization.
-
Ridge Regression: It is a linear regression with L1 regularization.
3. Clustering: Clustering or Cluster analysis is a way of grouping a set of objects of the same group. For example, different fruits such as apple, mango, oranges, and grapes are categories into separate sections. Here are some widely used clustering models.
-
K means: It is an unsupervised learning algorithm whose objective is to combine similar data points and find underlying patterns.
-
K means ++: It is a modified version of K means.
-
DBSCAN: This is a density-based clustering algorithm.
-
Agglomerative Clustering: This is a hierarchical-based clustering algorithm.
4. Dimensionality Reduction: Dimensionality Reduction is a process or technique to reduce the number of input variables in the dataset. More input variables make it more challenging and can overfit the model; this is generally referred to as the curse of dimensionality. Here are some commonly used models for dimensionality reduction.
-
PCA: PCA stands for Principal component Analysis. PCA helps to reduce the dimensionality of large data set into smaller ones, and new variables are independent of each other but less interpretable.
-
SVD: SVD stands for Singular Value Decomposition, which is used to decompose the matrix into smaller parts for efficient calculations.
5. Deep Learning: Deep Learning is considered a subset of machine learning based on artificial neural networks with representation learning. Here are some important deep learning models based on the architecture of neural networks.
-
Multi-Layer perceptron
-
Convolution Neural Networks
-
Recurrent Neural Networks
-
Boltzmann machine
-
Autoencoders, etc
There are many machine learning models, but how to figure out which is best? So, it depends upon the type of problem we are trying to solve and attributes associated with it, such as outliers, quality of data, the volume of data, feature engineering, and many more. Choosing a specific model is necessary to obtain the correct result for a machine learning problem. Evaluation metrics or KPIs are defined for particular business problems to find the performance between different models. After going through the statistical performance checking, the best model is selected for production.
It is always recommended to start with the simplest model first and then increase the complexity by proper parameter tuning and cross-validation. In the world of data science, it is said, “Cross-validation is more trustworthy than domain knowledge.”